

こんにちは、CCCMKホールディングス TECH LABの三浦です。
なんだか急に気温が下がり、秋めいてきました。秋は美味しいものが多く、外を歩くのも気持ちがいいので一年で一番好きな時期です。
LLM AgentはLarge Language Model(LLM)にWeb APIやデータベース検索機能をツールとして与え、ユーザーの入力に対してそれを解くための計画を作らせ、必要なツールを実行し、その結果を使って回答を生成させる手法です。LLMを有効に活用する方法として、LLM自体の性能向上と並行して注目しています。
LLM Agentはユーザー目線で見れば入力した質問に対して回答が返ってくるだけですが、実際には入力と出力の間に複数回LLMへの問い合わせが発生したり、別のアプリケーションを起動したりデータベースへの問い合わせ処理など、複数の処理が実行されます。
開発側の目線で見ればユーザーが求める回答が得られなかった場合に、その原因を突き止めるために途中に発生する全ての処理の結果を押さえておきたいと考えます。また途中の処理でエラーが発生した場合の原因特定、入力から出力までに時間がかかっている時どこでスタックしているのかを調査する必要もあります。
このようにLLM Agentの中間処理をさかのぼる(トレーシングする)ことをサポートするツールやサービスは色々と提供されています。その中で特に機械学習のログ管理で触ることが多いMLflowに"MLflow Tracing"という機能が追加されていることを最近知りました。私は機械学習系のプロジェクトはAzure Databricksでノートブックを作り学習処理をクラスター上で実行し、学習処理中の指標や学習したモデルファイルの保存をMLflowで行っています。これまでの機械学習プロジェクトと同様、LLM AgentでもMLflowを活用できることは個人的にもとてもありがたいことだったりします。
今回はAzure DatabricksのノートブックでLangChainを使った基本的なLLMのプログラムを作って実行し、MLflow Tracingで内部処理がどのように記録されるのかを確認してみました。
MLflow Tracingを使うために
MLflow TracingについてはMLflowのドキュメントに記載されています。
ドキュメントによると、MLflow Tracingのサポートは"MLflow 2.14.0"から開始されているようです。LangChain, LangGraph, OpenAI, LlamaIndex, AutoGenといった代表的なLLMアプリケーション開発ライブラリと統合されていて、これらのライブラリを使ったプログラムのトレーシングはmlflow.<library名>.autolog()のようなコマンドを1行実行するだけですぐに開始することが出来ます。もちろん独自に作成した関数の実行をトレーシング対象にすることも可能です。その方法を使うことで前回の記事で触れたHayStackを使う場合もトレーシングすることが出来そうです。
LangChainを使う場合はMLflowのドキュメントに簡単なコードサンプルが掲示されています。そちらのサンプルを実行するために必要なPythonのライブラリにRAGやAgent実行に必要になるものを加えた次のライブラリ一式をDatabricksのノートブックからインストールしました。
%sh pip install \ openai==1.30.5 \ langchain==0.2.1 \ langchain-chroma>=0.1.2 \ langchain-openai==0.1.8 \ langchain-community==0.2.1 \ langchain-text-splitters \ mlflow==2.14.0 \ tiktoken==0.7.0
インストール後、Pythonのプロセスの再起動を行いました。
dbutils.library.restartPython()
また、Azure OpenAI Serviceを利用するためあらかじめノートブックを実行するドライバノードの環境変数AZURE_OPENAI_ENDPOINTにAzure OpenAI ServiceのリソースのURL、AZURE_OPENAI_API_KEYにAPIキーをセットしておきました。
Chatモデルへの入出力の記録
では基本形として、Chatモデル"gpt-4o"へいくつか入力を与え、出力された結果をMLflow Tracingで記録してみます。次のようなコードを作成しました。
# langchain automatic tracingを使う from langchain_core.messages import ChatMessage, SystemMessage, HumanMessage from langchain_core.prompts import ChatPromptTemplate, HumanMessagePromptTemplate from langchain_openai import AzureChatOpenAI import mlflow mlflow.set_tracking_uri("databricks") experiment_name = "/path/to/mlflow-tracing" mlflow.set_experiment(experiment_name) mlflow.langchain.autolog() # LLM llm = AzureChatOpenAI( model="gpt-4o", openai_api_version="2024-07-01-preview", ) # prompt chat_message = ChatPromptTemplate([ SystemMessage(content="あなたは親切なアシスタントです。"), HumanMessagePromptTemplate.from_template("{query}"), ]) # chain chain = chat_message|llm # test queriew queries = [ "おはようございます", "こんにちは", "こんばんは" ] # run [chain.invoke({"query":query}) for query in queries]
このコードではgpt-4oに与えるプロンプトテンプレートを定義して、3つのテキストを入力し、それぞれに回答を出力させる処理を実行しています。
このコードをノートブックで実行すると、実行したセルの直下に次のような表示がされました!
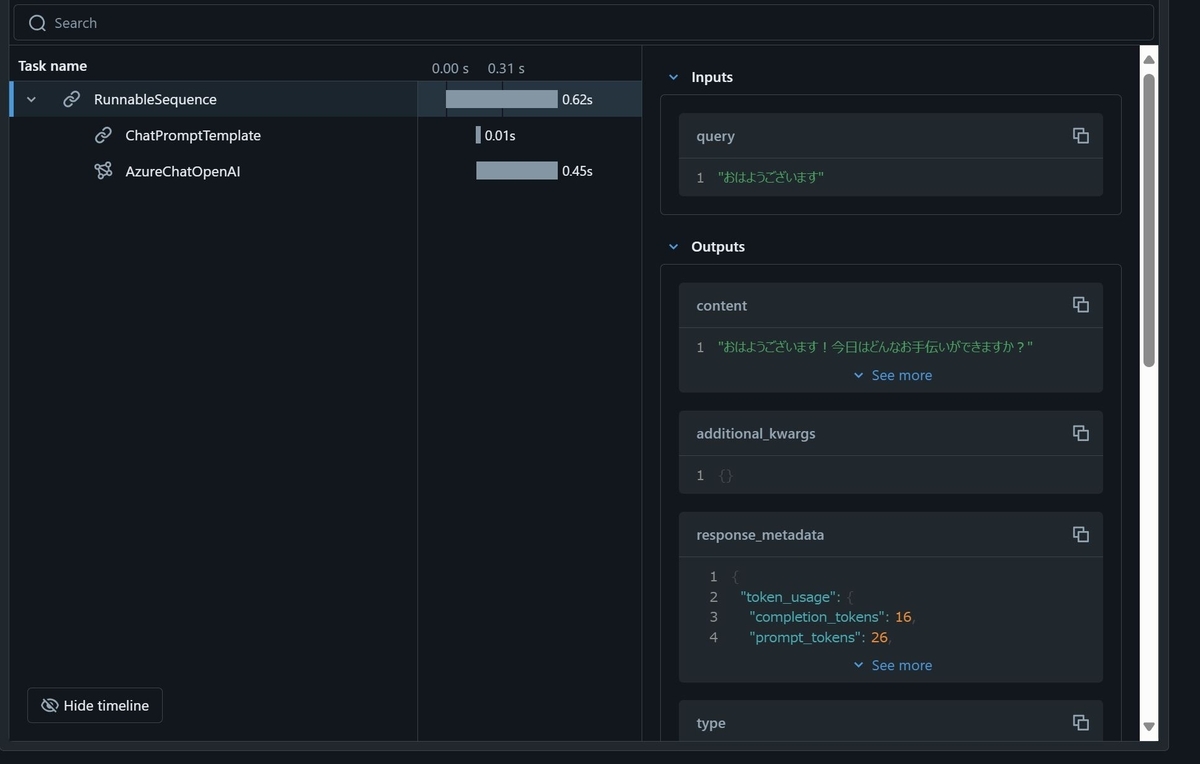
まさかノートブック上に表示されるとは予想していなかったので、ちょっとびっくりしました。入力テキストごとにページわけがされていて、回答生成までにかかった中間処理の時間や入出力を確認することが出来ました。
Experimentのどこに記録される?
ノートブックで記録を確認することが出来たのですが、MLflowのExperimentのどこに結果が記録されるのかをすぐに見つけることが出来ませんでした。普段DatabricksでMLflowに記録を行うとExperimentの下に自動的にRunが生成されその中に結果が記録されることが多いです。今回もきっとどこかにRunが生成されてその中に結果が記録されているはず・・・!と思って探していたのですが、MLflow Tracingの場合は実はRunが生成されず、Experimentの直下に結果が記録されていることが分かりました。
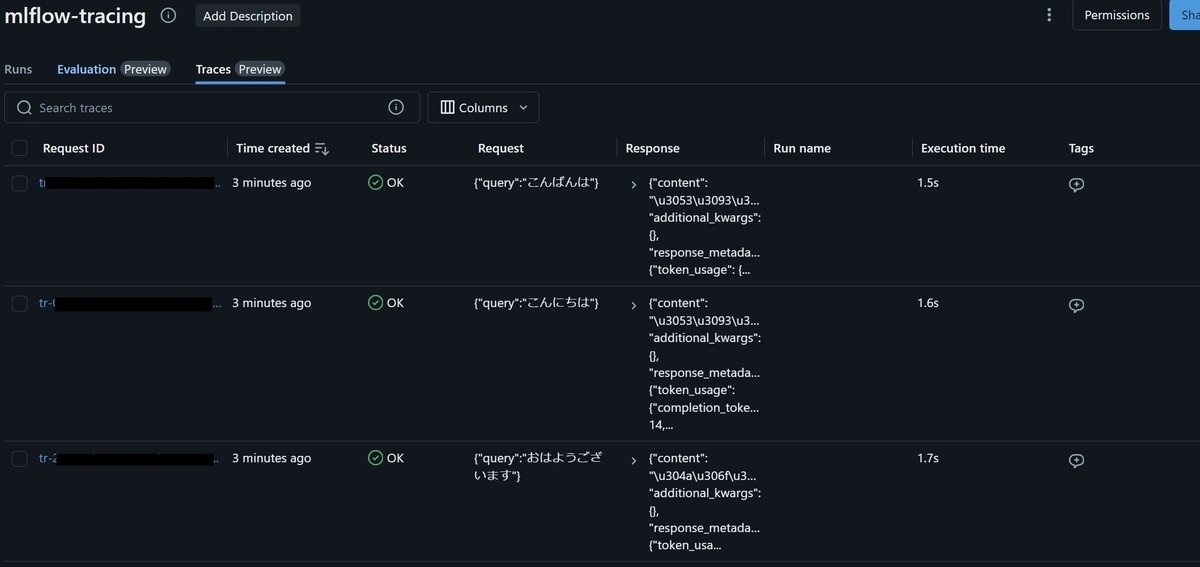
具体的にはExperimentを開き、画面上部の"Traces"をクリックすることでこれまでにこのExperimentに記録されたMLflow Tracingの結果を確認することが出来ます。
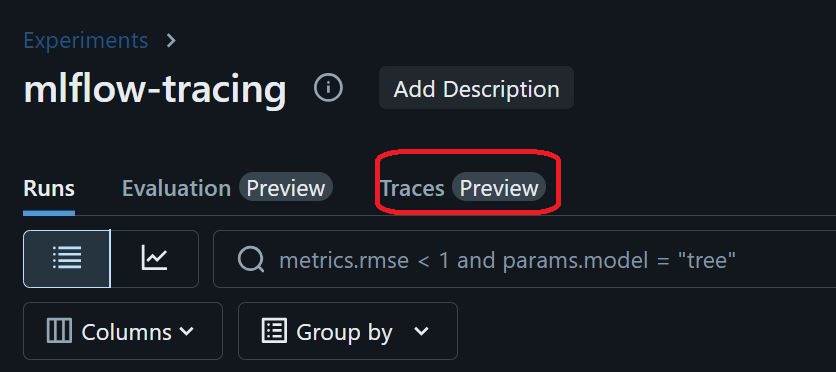
結果を表示した様子。
Agentの記録
次にLangChainで構築したLLM Agentの記録をMLflow Tracingで付けてみました。今回作成したAgentは"Tool calling agent"と呼ばれるもので、ユーザの入力に対して必要に応じて与えられたツールを実行して回答を生成する、という動作をします。
今回与えるツールは前回私が書いた"Haystack"というフレームワークに関するブログ記事から関連する情報を取得することが出来るものです。
それではツールの構築から含めて実装をまとめていきます。
ドキュメントを取り込み、検索可能な状態にする
最初に前回のブログ記事をHTMLファイルとして保存したファイルをドキュメントとして読み込み、ベクトルDB化・検索可能な状態にするところまでの実装です。
HTMLファイルの読み込み。
from langchain_community.document_loaders import BSHTMLLoader loader = BSHTMLLoader("/path/to/blog.html") docs = loader.load()
テキストを分割するチャンキング処理の実行。
from langchain_text_splitters import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=50, length_function=len, is_separator_regex=False, ) splitted_docs = text_splitter.split_documents(docs)
埋め込みベクトルの生成とベクトルDBの生成処理。
from langchain_chroma import Chroma from langchain_openai import AzureOpenAIEmbeddings embedding = AzureOpenAIEmbeddings( model="text-embedding-ada-002", api_version="2024-07-01-preview", ) db = Chroma.from_documents(splitted_docs, embedding=embedding) retriever = db.as_retriever()
構築したretrieverをテストしてみます。
retriever.invoke("haystackとは?")
するとノートブック上に次のような表示がされました。
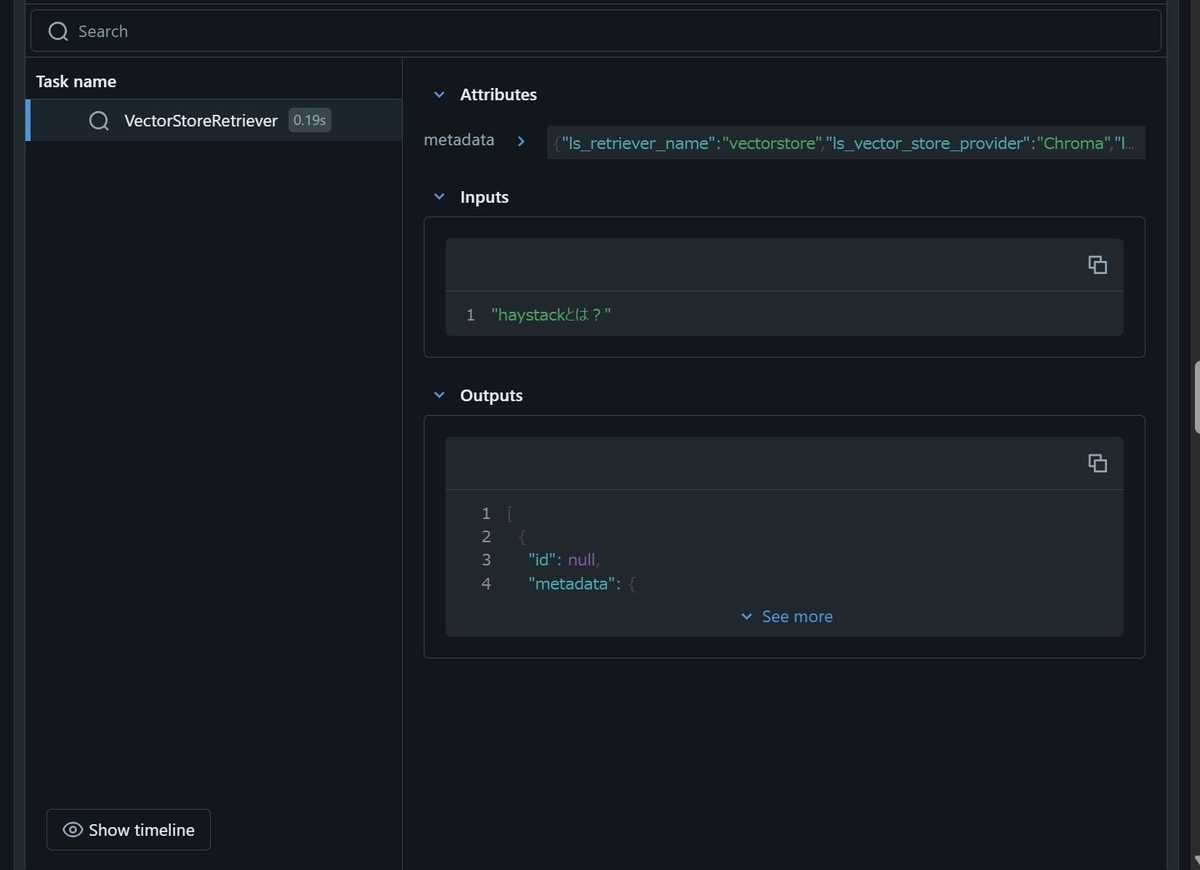
どうも一度mlflow.langchain.autolog()を実行すると、以降このノートブック上でLangChainの処理を実行する度にこのように結果が表示されるようです。
このままでもいいのですが、場合によっては都度表示されると煩わしく感じることもあるかもしれません。その場合、次のコマンドを実行することで表示させないようにすることが出来ます。
mlflow.tracing.disable()
Retrieval Chainの構築
先ほど作成したretrieverは入力したテキストに関連するブログ内のテキストを返す動きをします。ベーシックなRAGだとユーザの質問文をそのままretrieverの入力に使いますが、かならずしも質問文が検索に適したテキストであるとは限りません。
たとえば"Haystackについて分かりやすく300文字程度でレポートして。"というユーザのAgentへの入力をそのままretrieverへ与えるよりも、"Haystackとは"というテキストをretrieverに与えた方がより適した情報を取得出来る可能性が高いです。
そこで次のように質問を検索用クエリに書き換える指示(rewrite_query)を挟むことで回答精度の向上が期待されます。
from langchain_core.output_parsers import StrOutputParser rewrite_query = ChatPromptTemplate([ SystemMessage(content="与えられた質問を調べるために必要な検索用クエリを作成してください。検索用クエリのみ出力するようにしてください。"), HumanMessagePromptTemplate.from_template("{query}"), ]) retrieval_chain = rewrite_query|llm|StrOutputParser()|retriever
ツールの定義
Agentに与えるツールを、関数で定義します。
from langchain.agents import AgentExecutor, create_tool_calling_agent from langchain.tools import tool @tool def execute_retrieval_chain(query: str)->str: """ 質問に対して関連情報の検索を行い、結果を返すツールです。 """ retriever_result = retrieval_chain.invoke({"query": query}) return_str = "" for result in retriever_result: return_str += f"title: {result.metadata['title']}, content: {result.page_content}\n" return return_str tools = [execute_retrieval_chain]
Agentの定義
あとは次ようにツールを与えたAgentを構築すれば完成です。
prompt = ChatPromptTemplate.from_messages(
[
SystemMessage(
content="あなたは親切なアシスタントです。情報の検索にexecute_retrieval_chainを活用して下さい。"
),
("placeholder", "{chat_history}"),
HumanMessagePromptTemplate.from_template("{query}"),
("placeholder", "{agent_scratchpad}"),
]
)
agent = create_tool_calling_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools)
実行
実行する前に、もしmlflow.tracing.disable()を実行している場合は次のコマンドを実行してTracingをONにしておきます。
mlflow.tracing.enable()
そしたら次のコマンドでAgentを実行します。
agent_executor.invoke({"query": "Haystackについて説明してください。"})
すると次ようにAgentの中で実行された処理内容を細かく見ることが出来る画面がノートブック上に表示されました。
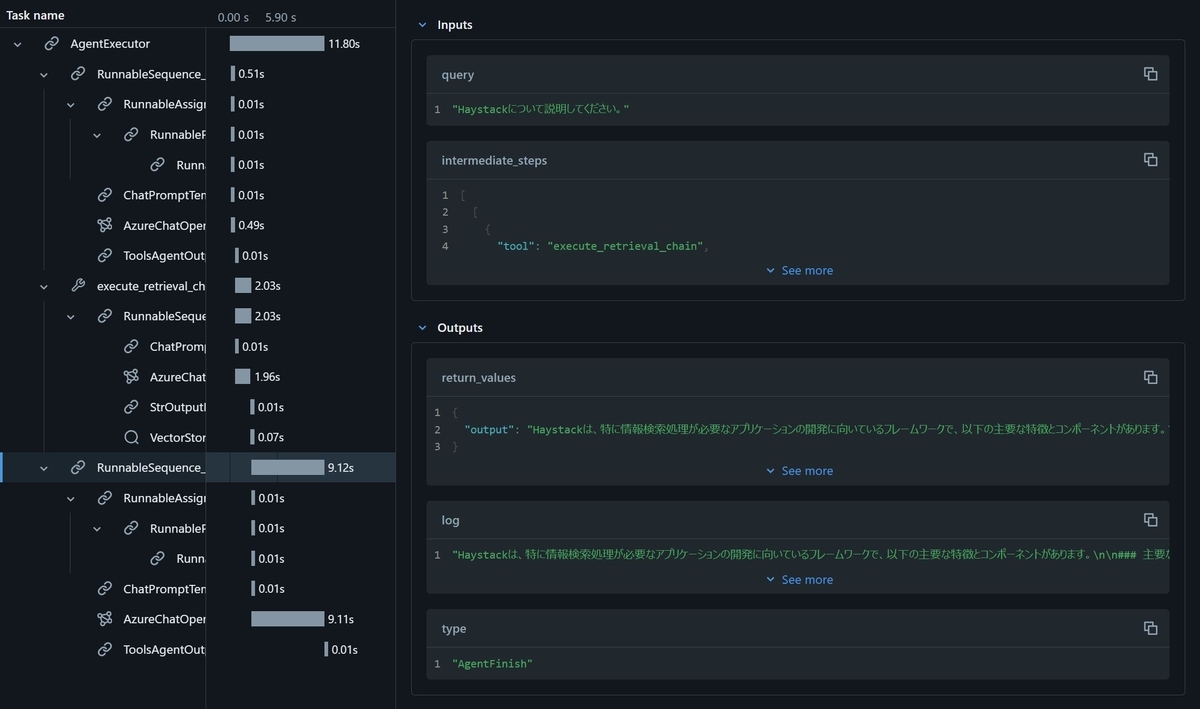
この結果を見ると、入力から応答まで11.80秒かかっていて、その大半が最後のAzure OpenAI Serviceの処理に費やされていることが分かります。このようにして複雑なAgentの処理の内部まで確認し、どこに課題があるのかを検知することがMlflow Tracingを使うことで可能になります。
まとめ
ということで、今回はLLM Agentの内部で実行される処理の記録に役立つMLflow TracingをDatabricksで利用してみました。普段機械学習プロジェクトで使い慣れているDatabricksやMLflowでLLM Agentを同様に開発することが出来そうです。