
 こんにちは。データサイエンスグループの木下です。
弊社では、デジタル広告の運用を行っておりますが、基本的に配信数に比例して金額がかかってくるため、
なるべくコンバージョンしてくれそうな人に配信する必要があります。
そこで、CTR予測に特化したDNNモデルを実装したpythonライブラリであるDeepCTRの中から、
ESMMというモデルを使ってみました。
こんにちは。データサイエンスグループの木下です。
弊社では、デジタル広告の運用を行っておりますが、基本的に配信数に比例して金額がかかってくるため、
なるべくコンバージョンしてくれそうな人に配信する必要があります。
そこで、CTR予測に特化したDNNモデルを実装したpythonライブラリであるDeepCTRの中から、
ESMMというモデルを使ってみました。
ESMMの特徴
まず、ESMMについて説明します。
ESMMとはEntire Space Multi-Task Modelの略です。
デジタル広告のCVR予測タスクにおける、
インプレッション→クリック→コンバージョン
という時系列を意識したマルチタスクモデルです。先にモデルの構造を見てみましょう
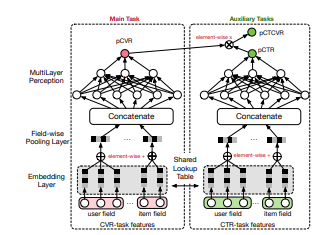
ユーザ情報とアイテム情報を入力して埋め込み表現を作り、それらを結合した後にNNを通してpCVRとpCTRとpCTCVRという3つの確率値を出しています。それぞれの確率値の意味は下記のとおりです。
pCTR ・・・ ユーザーが広告をクリックする確率
pCVR ・・・広告をクリックしたユーザーがコンバージョンする確率
pCTCVR ・・・ ユーザーが広告をクリックしてコンバージョンする確率
また、pCTCVR = pCTR×pCVR が成り立ちます。
ちなみに全体のユーザーは広告がインプレッションされた人に限定しています。
このモデル構造により、CVR予測モデル全般において発生してしまう下記2点の問題を解決することができます。
sample selection bias (SSB)
一般的なモデル:
pCVRはclickした人の中で学習するが、推論するときはimpression者全体の中で推論してしまい、SSBが発生してしまう。
ESMM:
損失関数をpCVRにせず、pCVRとpCTCVRの和にすることで、impression者空間で学習していることになり、SSBを解消できる。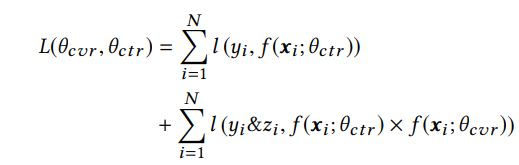
損失関数 Data Sparsity (DS)
一般的なモデル:
click者のデータ規模は一般的にimpression者の4%程度しかないDS問題が発生している。
ESMM:
CVRタスクの際にCTR予測タスクの埋め込み表現を用いることでDS問題を解決している。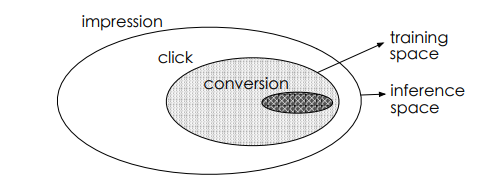
SSB
ESMMの使い方
ESMMを使って予測を行うコードについて解説します。 この下のコードは、DeepCTRをtorchで実装したDeepCTR-torchによる実装になります。 DeepCTRは下記のようにたくさんのモデルが実装されていますが、どのモデルも基本t系には関数名さえ変えれば動くように設計されています。後ほど出てきますが、ESMMはクリックとコンバージョンの2種類の目的変数を指定する点が他のモデルと違います。
①ライブラリインポート
from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder, MinMaxScaler from deepctr_torch.models import ESMM from deepctr_torch.inputs import SparseFeat, DenseFeat, get_feature_names
下記の2行がDeepCTRの関数になります。 ESMMがモデルそのものの関数、それ以外はDeepCTR共通の変数に特定の処理をする関数になります。
②データの前処理
# カテゴリ変数のラベルエンコーディング for feat in sparse_features: lbe = LabelEncoder() df[feat] = lbe.fit_transform(df[feat]) # 正規化 mms = MinMaxScaler(feature_range=(0, 1)) df[sparse_features] = mms.fit_transform(df[sparse_features])
下記で説明しますが、sparse_featuresはカテゴリカル変数のカラム名の配列です。
③数値変数とカテゴリ変数の指定
fixlen_feature_columns =
[SparseFeat(feat,vocabulary_size=df[feat].nunique(),embedding_dim=4)
for i,feat in enumerate(sparse_features)]
+ [DenseFeat(feat, 1,) for feat in dense_features]
dnn_feature_columns = fixlen_feature_columns
DeepCTR内では、数値変数をDenseFeat関数、カテゴリカル変数をSparseFeat関数に入れることでモデルに入力できる状態に変換してくれます。 dense_featuresは数値変数のカラム名の配列です。
④学習
train, test = train_test_split(df, test_size=0.2, random_state=100) train_model_input = {name: train[name] for name in ] get_feature_names(dnn_feature_columns)} test_model_input = {name: test[name] for name in get_feature_names(dnn_feature_columns)} model = ESMM(dnn_feature_columns,device='cpu') model.compile("adagrad", "binary_crossentropy","auc") model.fit(train_model_input, train[['click','conversion']].values, batch_size=32, epochs=15, verbose=2, validation_split=0.2)
ここでは、ESMMのモデルのインスタンスを作成し、compile関数で学習方法を指定したのち、fit関数で学習させます。
最後の行のfit関数の、2つ目の引数が目的変数になります。 ESMMではclickとconversionの2種類の目的変数を入力する必要があります。 カラム名は適宜変更してください。
⑤推論
pred_ans = model.predict(test_model_input, batch_size=256)
predict後の戻り値はpCTRとpCTCVRの2列になることに注意してください。
以上がDeepCTR-torchを用いたESMMの使い方になります。
DeepCTR-torchのドキュメントにはESMMの実装方法は記載されていませんでしたので、 ぜひ参考にしてみてください。