

はじめに
こんにちは、CCCMKホールディングスAIエンジニアの三浦です。
前回Azure DatabricksでUnity CatalogのTableの内容を参照して回答するAgentアプリケーションをLangGraphで構築した話をご紹介しました。
Notebookで動かすところまでは進められたものの、この機能をAPIで提供しようとDatabricksのModel Servingにデプロイしたところ、Model ServingからTableが参照できない、といった課題が見つかりました。
どうやったら解決できるんだろう、と色々調べていたところ、"Genie"というDatabricksの機能を使うとやりたいことが実現できることが分かりました。
今回はGenieとLangGraphでAgentアプリを構築し、Model Servingにデプロイ、Model Serving Endpointにリクエストを投げて結果を得るところまでを実現することが出来たので、ご紹介したいと思います!
Genie
Genieは自然言語でUnity Catalogに格納されたデータに問い合わせをすることが出来るDatabricksの機能です。
このドキュメントにはGenieがどのように動作するのかが説明されています。その中で特に
- Genieはユーザーの質問に対しSQLクエリを生成し、クエリを実行し、結果を返す
- SQLクエリを生成する際はユーザーの質問と対象のTableのメタデータを参照する
- SQLの生成はAzureの場合、Azure OpenAI Serviceのモデルを使用する
- Azure OpenAI ServiceにはTableのローデータは送信されない
といった点が重要なポイントだと思います。
ドキュメントを読み、Genieの処理の内容をまとめてみた図がこちらです。
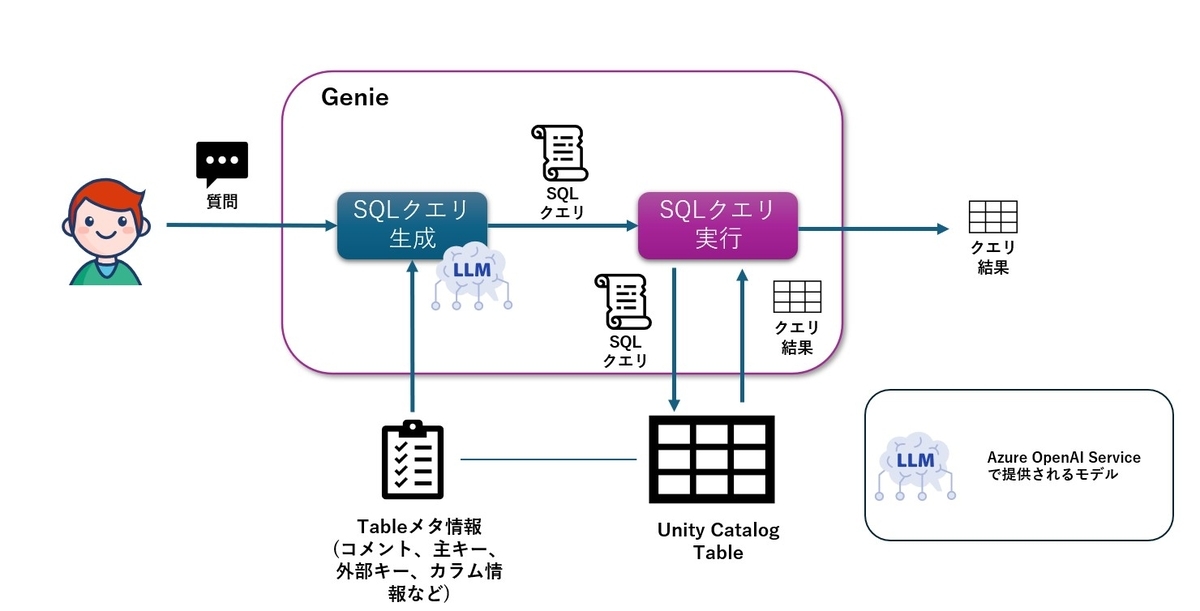
アプリケーションの処理の全体図
前回作ったアプリケーションの処理は以下のようになっていました。
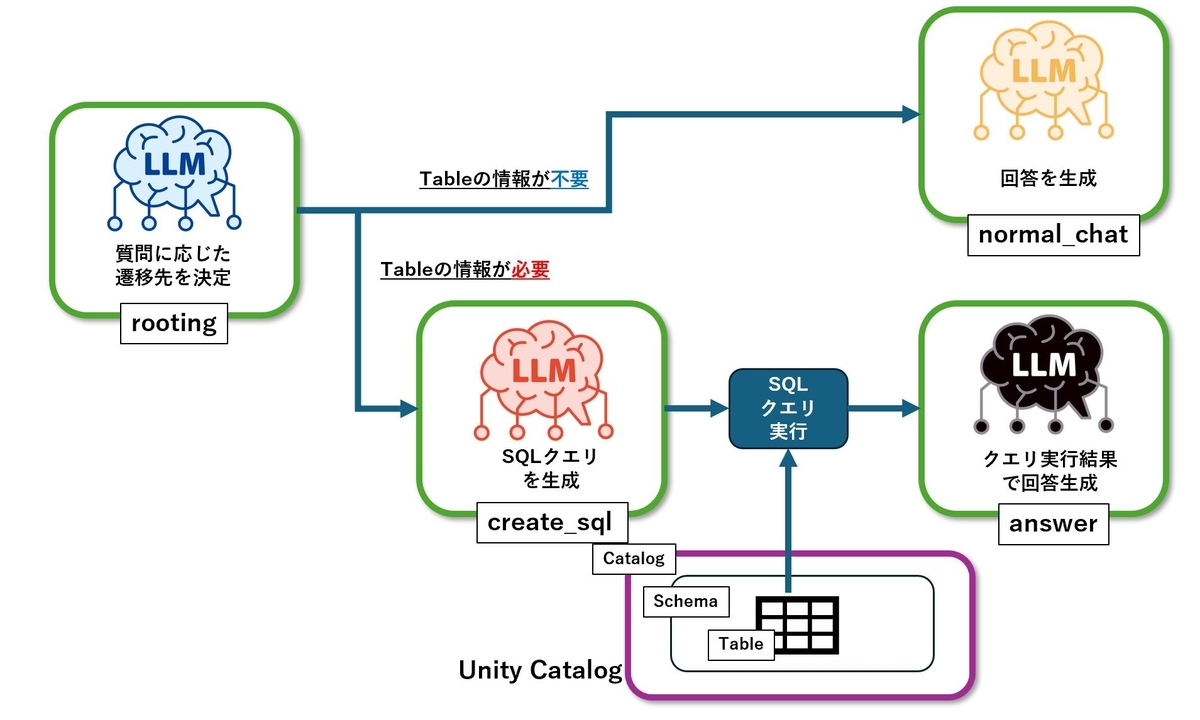
この図の中の"create_sql"と"SQLクエリ実行"の部分を、今回はGenieに置き換えます。GenieへのアクセスはAPIで可能です。前回と同様、全体の処理はAgent開発フレームワークLangGraphで実装し、Nodeの中にGenieの呼び出し処理を実装します。
今回の処理は次のようになります。
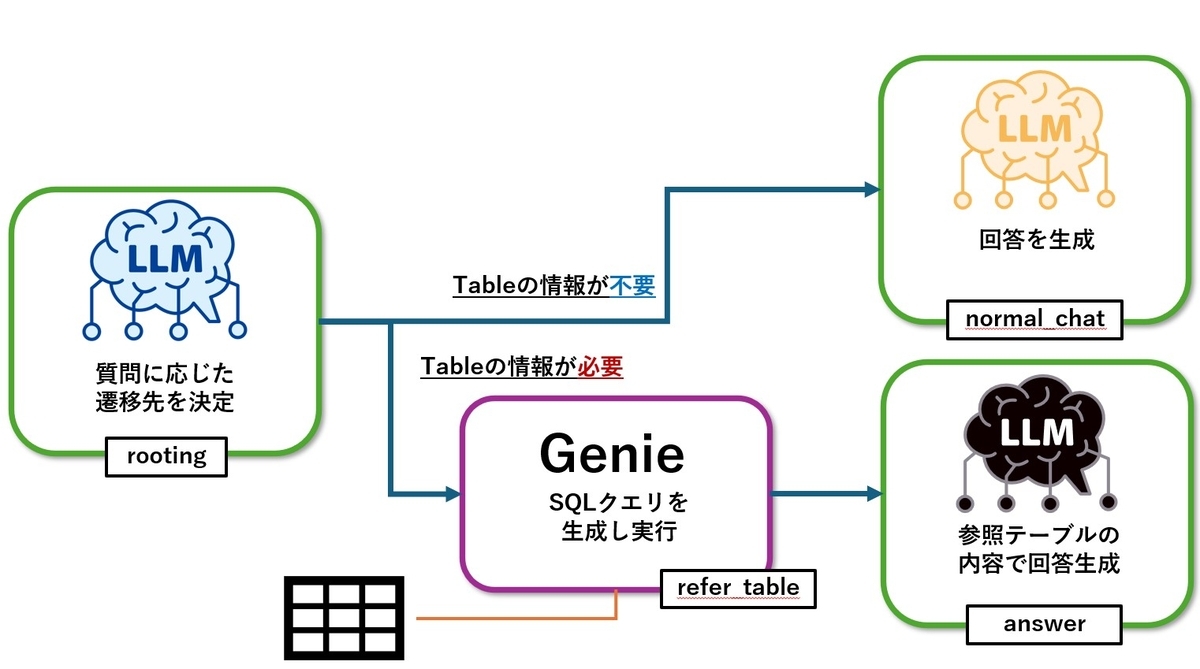
また、今回もHugging Faceのこちらのデータセットを参照データとして使用しています。
アプリケーション構築手順
ここからはアプリケーションを構築し、Model Servingにデプロイするまでの手順をまとめます。
Genieの作成
最初にDatabricksでGenieの作成を行います。具体的には参照させるUnity CatalogのTableの指定と、質問とSQLクエリの例を設定しました。
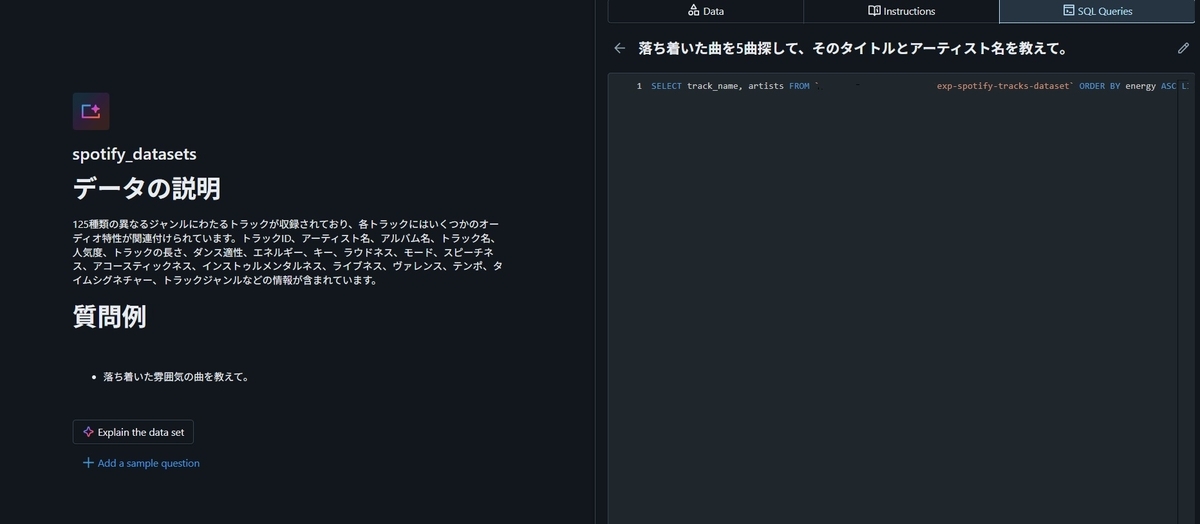
触ってみた感じですが、質問とSQLクエリの例は含めたほうがよいと思いました。たとえば"エネルギーにあふれた曲を教えて"という質問に対し、SQLクエリ例がないと属性値"energy"の降順でソートした結果を全件返すSQLクエリが生成されたのですが、理想はその上位数件を返す"LIMIT"を含めたSQLクエリです。そこでそれを例として与えると、望ましい動きを実現することが出来ました。
また、Genieの設定画面のURL文字列を見ると"https://adb-xxxxx.azuredatabricks.net/genie/rooms/xxxxx?sp=..."のようになっているのですが、"room/"以降の文字列は"Genie Space ID"と呼ばれ、APIでGenieにアクセスする際に必要になる情報です。
PATのシークレットへの登録
GenieにAPIでアクセスする際にPersonal Access Token(PAT)が必要になります。PATを作成し、シークレットに登録する作業を行いました。
PATの発行はこちらの手順で行いました。
シークレットへの登録はこちらの手順に記載されている、Databricks CLIを使用した方法で登録しました。
NotebookからGenieにアクセスする
ここからは具体的な実装に入りますが、実装はこちらのページに掲載されているExample Notebookの内容に沿っています。
まずLangGraphでアプリを開発し、Unity CatalogのModelとして登録するまでに必要になるライブラリ一式をインストールします。
%pip install databricks-langchain databricks-agents langgraph>=0.3 uv
dbutils.library.restartPython()
"uv"というライブラリはPythonのPackageとProject管理の役割を担っていて、これから作成するアプリケーションの実行環境をModel Serving上に再現する時に必要になります。
次にGenieにアクセスするために必要な各種情報を設定します。必要になるのは"Genie Space ID"とDatabricksのWorkspaceのURL、そしてPATです。PATはシークレットから取得します。
import os from dbruntime.databricks_repl_context import get_context GENIE_SPACE_ID = "Genie Space ID" secret_scope_name = "PATが登録されたシークレットスコープ名" secret_key_name = "PATが登録されたシークレットキー名" os.environ["DB_MODEL_SERVING_HOST_URL"] = "https://" + get_context().workspaceUrl os.environ["DATABRICKS_GENIE_PAT"] = dbutils.secrets.get( scope=secret_scope_name, key=secret_key_name )
これらの情報を使って、Genieにアクセスすることが出来るようになります。
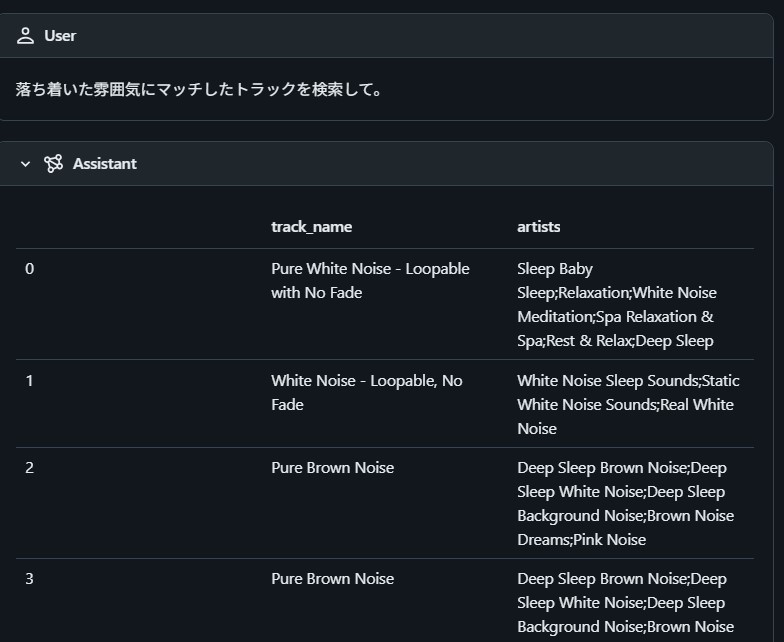
import os from databricks_langchain.genie import GenieAgent from databricks.sdk import WorkspaceClient description = \ """トラックID、アーティスト名、アルバム名、トラック名、人気度、トラックの長さ、ダンス適性、エネルギー、キー、ラウドネス、モード、スピーチネス、アコースティックネス、インストゥルメンタルネス、ライブネス、ヴァレンス、テンポ、タイムシグネチャー、トラックジャンルといった、音楽に関する情報を持ち、検索することが出来ます。""" genie = GenieAgent( genie_space_id=GENIE_SPACE_ID, genie_agent_name="music-answer-agent", description=description, client=WorkspaceClient( host=os.getenv("DB_MODEL_SERVING_HOST_URL"), token=os.getenv("DATABRICKS_GENIE_PAT") ) ) input = { "messages": [{"role":"user","content":"落ち着いた雰囲気にマッチしたトラックを検索して。"}] } genie.invoke(input)
次のような結果が得られました。入力した自然言語から、SQLクエリが生成され、そのクエリを実行したことで得られた結果が返ってきています。
LangGraphのGraphをスクリプトに書き出す
Notebookの1つのセルに、LangGraphのGraphを記述し、スクリプトに書き出します。セルに先頭に%%writefile genie_agent.pyのように記述して実行すると、セルの内容がスクリプトに書き出されます。
%%writefile genie_agent.py import os from typing import Annotated, Any, Generator, Literal, Optional from typing_extensions import TypedDict from databricks_langchain import ChatDatabricks from databricks_langchain.genie import GenieAgent from databricks.sdk import WorkspaceClient from langgraph.graph import StateGraph, END from langgraph.graph.state import CompiledStateGraph from langgraph.graph.message import add_messages from langgraph.types import Command import mlflow from mlflow.pyfunc import ChatAgent from mlflow.types.agent import( ChatAgentChunk, ChatAgentMessage, ChatAgentResponse, ChatContext, ) LLM_ENDPOINT = "databricks-meta-llama-3-3-70b-instruct" GENIE_SPACE_ID = "Genie Space ID" # Genie description = \ """トラックID、アーティスト名、アルバム名、トラック名、人気度、トラックの長さ、ダンス適性、エネルギー、キー、ラウドネス、モード、スピーチネス、アコースティックネス、インストゥルメンタルネス、ライブネス、ヴァレンス、テンポ、タイムシグネチャー、トラックジャンルといった、音楽に関する情報を持ち、検索することが出来ます。""" genie = GenieAgent( genie_space_id=GENIE_SPACE_ID, genie_agent_name="music-answer-agent", description=description, client=WorkspaceClient( host=os.getenv("DB_MODEL_SERVING_HOST_URL"), token=os.getenv("DATABRICKS_GENIE_PAT") ) ) # LLM llm = ChatDatabricks(endpoint=LLM_ENDPOINT) class State(TypedDict): messages: Annotated[list, add_messages] query_result: str class Rooting(TypedDict): direction: Literal["refer_table", "normal_chat"] def rooting(state: State): """StructuredOutputでクエリに対してDB問い合わせが必要かどうか判断する""" query = state["messages"][-1].content llm_with_structured = llm.with_structured_output(Rooting) prompt = \ f"""与えられた質問に対し、音楽作品やアーティストの参照が必要な場合は"refer_table"を、それ以外は"normal_chat"を出力してください。 質問: {query}""" output = llm_with_structured.invoke(prompt) if output["direction"] == "refer_table": return Command(goto="refer_table") else: return Command(goto="normal_chat") def normal_chat(state: State): """ユーザーの入力に対してデータベースを参照せずに回答する""" query = state["messages"][-1].content prompt = \ f"""ユーザーの入力に回答してください。 入力: {query} 回答: """ output = llm.invoke(prompt) return Command( goto=END, update={ "messages": [ {"role":"assistant","content":output.content,"id":output.id} ] } ) def refer_table(state: State): """ユーザーのクエリに回答するために必要な情報をGenieを使って取得する""" genie_response = genie.invoke( {"messages":[state["messages"][-1]]} )["messages"][-1].content return Command(goto="answer", update ={"query_result": genie_response}) def answer(state: State): """ユーザーの質問にデータベースの結果を使って回答する""" query = state["messages"][-1].content query_result = state["query_result"] analyze_prompt = \ f"""あなたは音楽に詳しいアシスタントです。 与えられた情報は、ユーザーの質問に対し答えるために必要な情報をデータベースから抽出したものです。 この情報を使ってユーザーの質問に答えて下さい。 # データベースから取得した情報 {query_result} 質問: {query} 回答: """ output = llm.invoke(analyze_prompt) return Command( goto=END, update ={"messages": [{"role":"assistant","content":output.content,"id":output.id}]} ) # Build Graph def build_graph(): graph_builder = StateGraph(State) graph_builder.add_node("rooting", rooting) graph_builder.add_node("normal_chat", normal_chat) graph_builder.add_node("refer_table", refer_table) graph_builder.add_node("answer", answer) graph_builder.set_entry_point("rooting") return graph_builder.compile() class LangGraphChatAgent(ChatAgent): def __init__(self, agent: CompiledStateGraph): self.agent = agent def predict( self, messages: list[ChatAgentMessage], context: Optional[ChatContext] = None, custom_inputs: Optional[dict[str, Any]] = None, ) -> ChatAgentResponse: request = {"messages": self._convert_messages_to_dict(messages)} messages = [] for event in self.agent.stream(request, stream_mode="updates"): for node_data in event.values(): if not node_data: continue messages.extend( ChatAgentMessage(**msg) for msg in node_data.get("messages", []) ) return ChatAgentResponse(messages=messages) def predict_stream( self, messages: list[ChatAgentMessage], context: Optional[ChatContext] = None, custom_inputs: Optional[dict[str, Any]] = None, ) -> Generator[ChatAgentChunk, None, None]: request = {"messages": self._convert_messages_to_dict(messages)} for event in self.agent.stream(request, stream_mode="updates"): for node_data in event.values(): yield from ( ChatAgentChunk(**{"delta": msg}) for msg in node_data["messages"] ) mlflow.langchain.autolog() app = build_graph() AGENT = LangGraphChatAgent(app) mlflow.models.set_model(AGENT)
Graphの登録
スクリプトに書き出したGraphをUnity CatalogのModelに登録します。最初にMLflowに記録し、そこからUnity Catalogに登録する、という手順を取ります。
以下でMLflowへの記録を行います。
import mlflow from mlflow.models.resources import ( DatabricksServingEndpoint, DatabricksGenieSpace ) from pkg_resources import get_distribution from genie_agent import GENIE_SPACE_ID, LLM_ENDPOINT # 関連するリソース resources = [ DatabricksServingEndpoint(endpoint_name=LLM_ENDPOINT), DatabricksGenieSpace(genie_space_id=GENIE_SPACE_ID) ] input_example = {"messages":[{"role":"user","content":"こんにちは"}]} with mlflow.start_run(): logged_agent_info = mlflow.pyfunc.log_model( python_model="genie_agent.py", artifact_path="agent", input_example=input_example, extra_pip_requirements=[ f"databricks-connect=={get_distribution('databricks-connect').version}" ], resources=resources )
次にUnity CatalogのModelに登録します。
mlflow.set_registry_uri("databricks-uc") catalog = "Catalog名" schema = "Schema名" model_name = "Model名" UC_MODEL_NAME = f"{catalog}.{schema}.{model_name}" # register the model to UC uc_registered_model_info = mlflow.register_model( model_uri=logged_agent_info.model_uri, name=UC_MODEL_NAME )
ここまではすべて1つのNotebook内で実行しました。
Model Servingへのデプロイ
ここからは別のNotebookで作業を進めました。
必要なライブラリのインストールをします。
%pip install databricks-agents dbutils.library.restartPython()
次を実行すると、Unity Catalogに登録したModelをModel Servingにデプロイすることが出来ます。 環境変数にPATを登録したシークレットの情報を渡す必要があります。
from databricks import agents secret_scope_name = "PATが登録されたシークレットスコープ名" secret_key_name = "PATが登録されたシークレットキー名" uc_model_name = "Catalog名.Schema名.Model名" version = 1 deployment = agents.deploy( uc_model_name, version, environment_vars={ "DATABRICKS_GENIE_PAT": f"{{{{secrets/{secret_scope_name}/{secret_key_name}}}}}" } ) # Retrieve the query endpoint URL for making API requests deployment.query_endpoint
これで新しいModel Serving Endpointが生成され、デプロイが完了するとモデルを利用することが出来るようになります。
Model Serving Endpointの使い方
デプロイが完了すると、DatabricksのUI上でReview Appを起動して会話形式でテストをすることが出来ます。

また、次のようにCurlコマンドを利用して利用することも出来ます。PATとEndpointのURLをセットする必要があります。
curl \
-u token:xxxxxxx \
-X POST \
-H "Content-Type: application/json" \
-d '{"messages":[{"role":"user","content":"気分が上がる音楽教えて"}]}'\
https://xxxxxxx/invocations
結果
{"messages":[{"role":"assistant","content":"気分が上がる音楽ですね。\n\nデータベースから抽出した情報によると、以下の楽曲が気分を上げるのに適しているようです。\n\n* Amigo Charly Brown by Jürgen Drews....."}}
まとめ
今回は前回実現することが出来なかった、Tableの情報を参照して回答出来るアプリケーションをModel Servingで提供するということを、DatabricksのGenieを使って実現してみました。以前から実現してみたかったことだったので、一通り自分で完遂することが出来てよかったです!