

はじめに
こんにちは、CCCMKホールディングス AIエンジニアの三浦です。
最近クラウドデータプラットフォーム"Snowflake"を色々と調べています。Snowflakeに含まれるLarge Language Model(LLM)を利用した"Snowflake Cortex"という機能が活用できそうだな、と感じたからです。
Snowflake CortexにはLLMを呼び出して感情分析などの定義済みの処理をSQL関数で利用できるCortex LLM FunctionsやRAGで利用するVector Search機能を提供するCortex Search, そして自然言語でTableデータに問い合わせが出来るCortex Analystなどの機能が含まれています。
今回はCortex Analystに注目し、概念や基本的な使い方を調べて実際に試してみました。
Cortex Analyst
Snowflake上のTableに対して自然言語で問い合わせることが出来る機能です。
LLMを利用してユーザーからの自然言語の問い合わせをSQLクエリに変換し、SQLクエリを対象のTableに実行する、という一連の流れを実行してくれます。ドキュメントによると使用されるLLMはデフォルトではSnowflake環境にホストされたLlamaとMistralのようです。
Cortex AnalystはSnowflake上のTableとLLMを紐づけるのですが、その際LLMに対象のTableを"どのように解釈させるのか"という情報を与えてあげる必要があります。たとえば"売上"というカラムがTableに含まれていた時に、それが"売上金額"なのか"売上数量"なのかを明示したり、税抜の金額はどのような計算式で求められるのか、といった情報を明示します。これらの情報はCortex Analystを利用する際に"Semantic Model"という対象のTableのメタデータを作成することでLLMに指示出来ます。
Semantic Model
Semantic ModelはYAMLファイルで定義し、その中にTableの説明、列の説明、列の別の呼び方(たとえば"商品"であれば"アイテム"といったような)、複数のTableを参照させる場合はTable間の関係性、質問とSQLクエリの例示などを含めることが出来ます。
特にLLMに、対象のTableにどのような情報が含まれ、どう扱うべきかを指示するために"Dimensions", "Time Dimensions", "Facts", "Filters", "Metrics"という概念があります。
Dimensions
Dimensionsに該当するデータは商品、顧客、場所などのカテゴリーデータで、それらを集計する際の集計軸、フィルタリングなどに利用できることをLLMに明示します。
Time Dimensions
日時、年、月といった時間間隔に対応するデータです。トレンドの特定や期間ごとの比較といった分析に使える情報であることをLLMに明示します。
Facts
Factsに該当するデータは売上やコストなどの量的なデータです。
Filters
クエリの結果をさらに条件で絞る方法をLLMに明示するために使用します。たとえば参照Table"nation"に"N_NAME"という国名を表すカラムがあった場合、"north_america"というフィルタをnation.N_NAME IN ('Canada', 'Mexico', 'United States')のように指示することが出来ます。
Metrics
Metricsは量的なデータとして指定したFactsに該当するデータをどのように集計するかを指示するために使用します。たとえば合計の"利益"を売上とコストで計算させる場合、合計利益=SUM(売上)-SUM(コスト)のように計算方法を明示的に示すことが出来ます。
"Filters"や"Metrics"は明示的に指定しなくてもある程度LLMが内容を理解してクエリを生成してくれるようです。ただ思ったようにクエリを生成してくれない場合や自然言語での指示がしにくい場合にはこれらが活用できると思います。
Cortex Analystを構築してみる
ここからは実際にCortex Analystを構築した時の手順をまとめていきます。
Snowflakeへのデータの格納
今回使用したデータは、以前も利用したHugging Faceで公開されているSpotifyのトラックデータセットです。
このデータをダウンロードして加工し、SnowflakeのTableとして格納します。データの加工はAzure DatabricksのNotebookで行いました。
必要なライブラリのインストールを行います。Snowflakeへの操作は、Snowparkというライブラリを使用して行いました。Snowparkの使い方は、以下のドキュメントを参照しました。
%pip install datasets python-dotenv snowflake-snowpark-python dbutils.library.restartPython()
Snowflakeへの接続情報(アカウント、ユーザー名、パスワード)は.envに記入しておき、Pythonのdotenvでロードして環境変数にセットしてから接続時に使用しました。
Snowflakeへの接続は以下のようにSessionを作り、Sessionを通じて行っていきます。
import os from dotenv import load_dotenv from snowflake.snowpark import Session load_dotenv() CONNECTION_PARAMETERS = { "account": os.environ["snowflake_account"], "user": os.environ["snowflake_user"], "password": os.environ["snowflake_password"], "role": "ROLE", # 接続時に使用するRole "database": "DB", # 接続先DB "warehouse": "WH", # 使用するWarehouse "schema": "SCHEMA", # 接続先SCHEMA } session = Session.builder.configs(CONNECTION_PARAMETERS).create()
Hugging Faceからデータセットをダウンロードします。
from datasets import load_dataset ds = load_dataset("maharshipandya/spotify-tracks-dataset")
PandasのDataFrameに変換し、不要なカラムを削除します。
df = ds["train"].to_pandas() df.drop("Unnamed: 0", axis=1, inplace=True)
"Snowpark"のDataFrameに変換し、Sessionを通じてTableに書き込みます。
df_table = session.create_dataframe(df) db = CONNECTION_PARAMETERS.get("database") schema = CONNECTION_PARAMETERS.get("schema") table = "SPOTIFY_TRACKS" df_table.write.mode("overwrite").save_as_table( f"{db}.{schema}.{table}" )
これでCortex Analystに参照させるTableをSnowflakeに格納することが出来ました。
Semantic Modelの構築
ここからはSnowflakeのWeb UI "Snowsight"を通じて作業を進めていきました。Semantic Modelは先にも述べたようにYAMLファイルで定義しますが、UIを通じて作ることが出来るので、1から直接YAMLを書く必要はありません。最初にUIでYAMLを作ってしまい、細かい調整を直接YAMLを編集して行うのがいいのでは、と思いました。
SnowflakeのAI&ML Studioから"Cortex Analyst"の"Try"に進み、表示される画面で"+Create new"をクリックします。
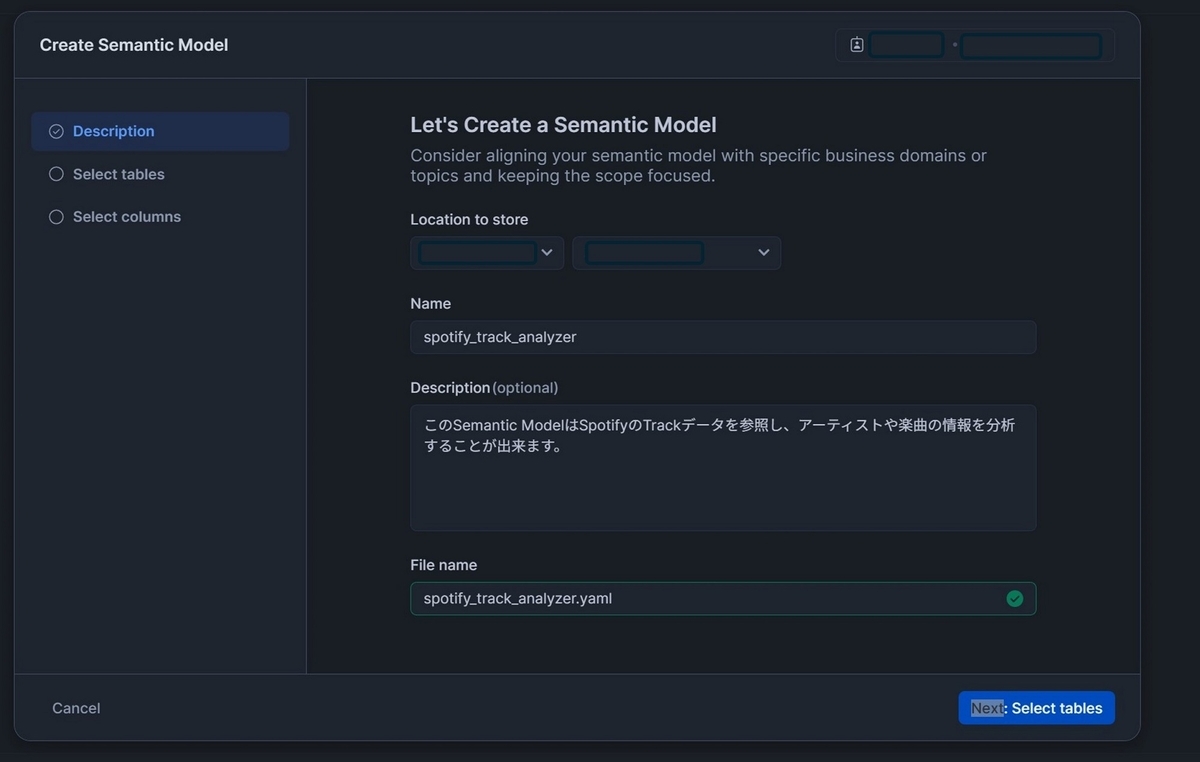
YAMLファイルの保存先のStage, ファイル名, 説明文を入力します。
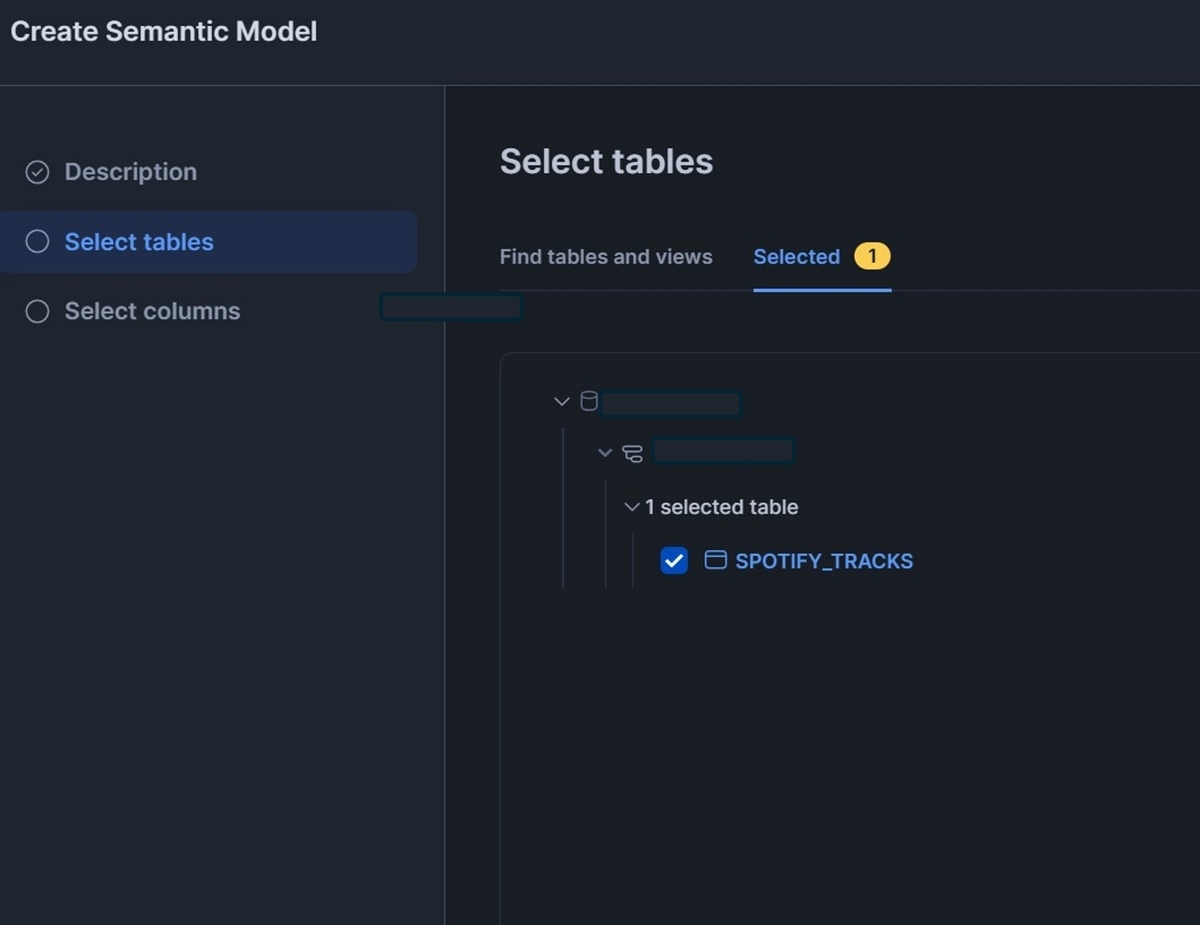
次に進み、参照させるTableを選択します。
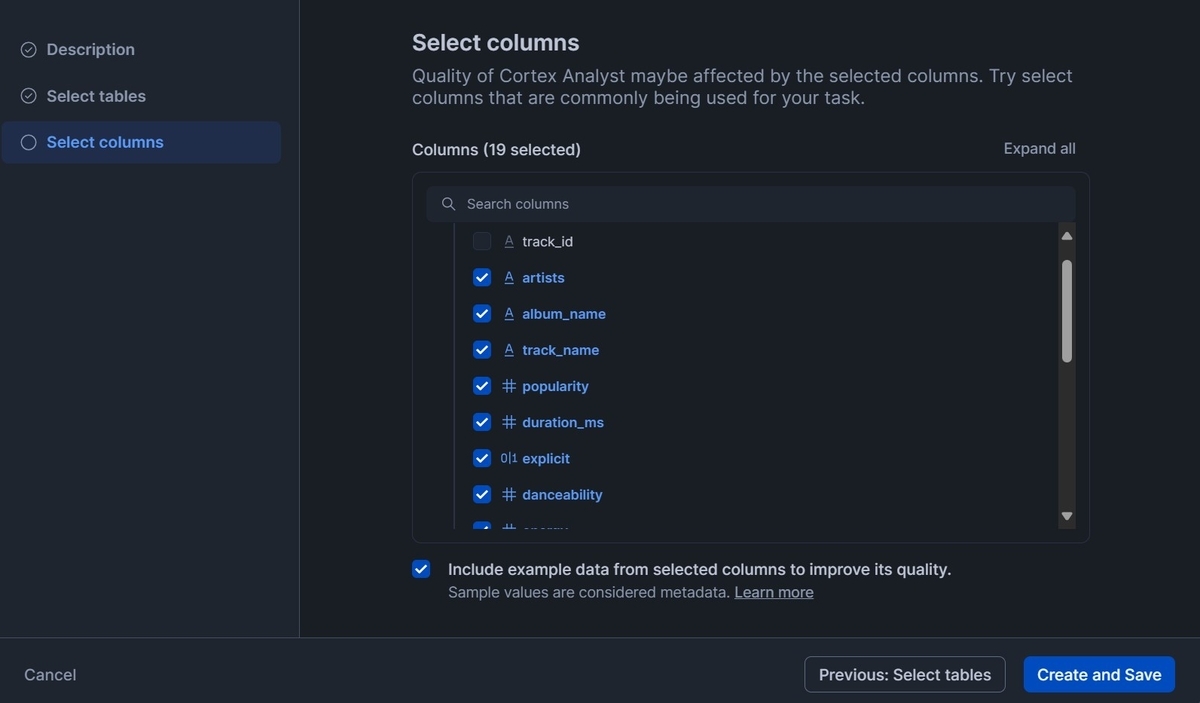
次に進み、使用するカラムを選択します。
あとは指定したTableの内容を元に、Semantic Modelが自動的に生成されます。
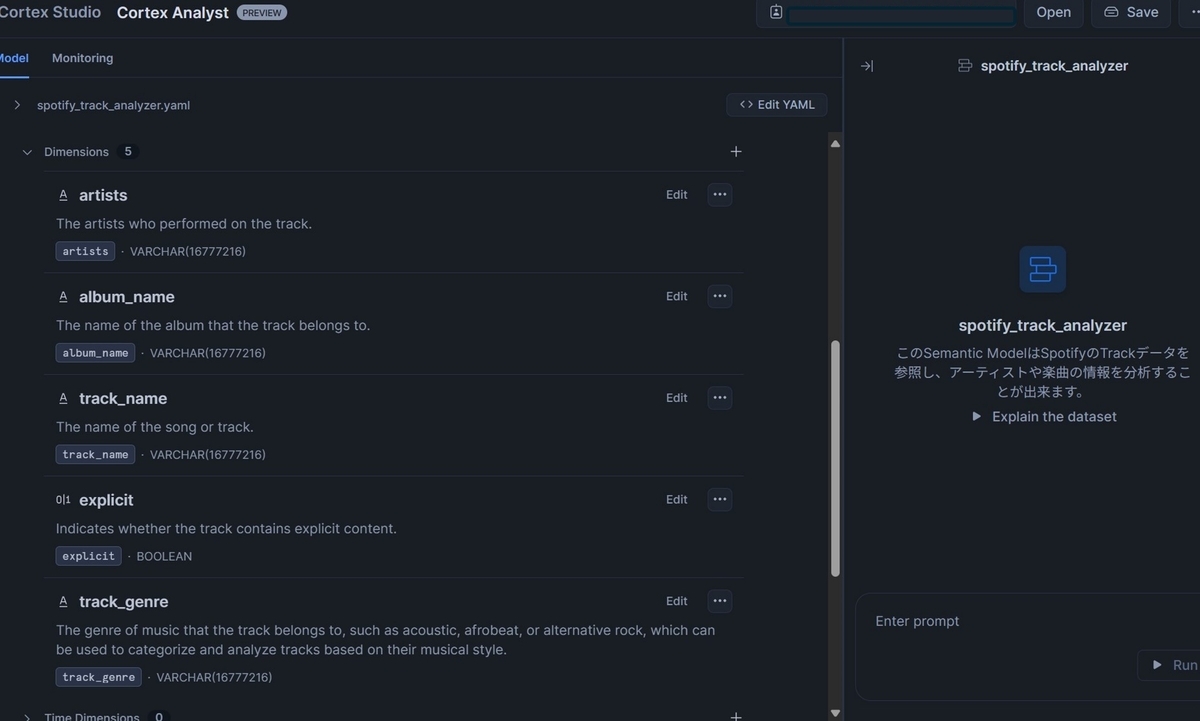
カラムのDimensionsやFactsへの振り分けや各カラムの説明などは自動的に生成されていました。内容も違和感のないものに仕上がっていました。
つまずいたポイント
さっそくCortex Analystにデータについて質問をしてみたのですが、思ったように回答を得ることが出来ませんでした。
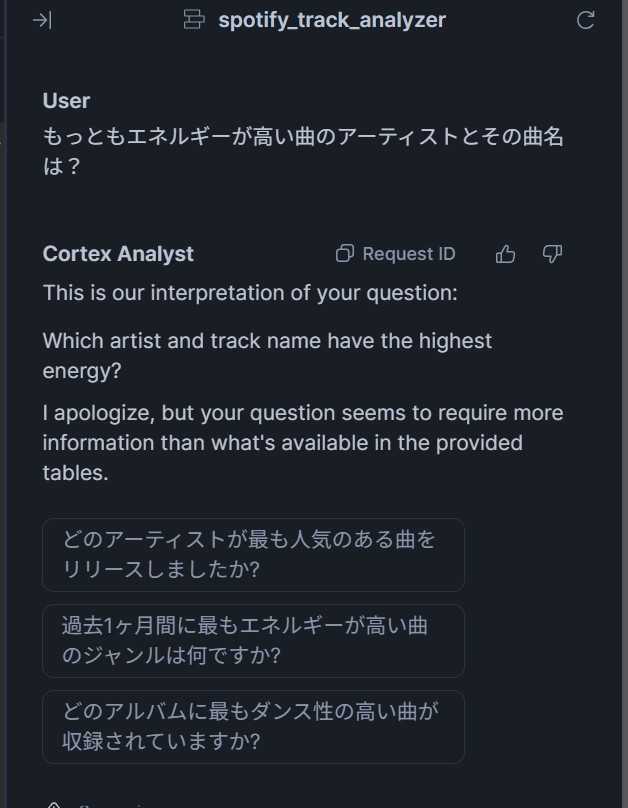
聞き方を変えてみたり、英語で聞いてみたりしたのですが、どうやっても回答を得ることが出来ません。しばらく調べてみたところ、いくつかの警告が出ており、その中に
SELECT track_name, energy FROM db.schema.spotify_tracks ) SELECT track_name FROM __spotify_tracks ORDER BY energy DESC NULLS LAST LIMIT 1;, Errors: ["SQL compilation error: error line 3 at position 4\ninvalid identifier 'TRACK_NAME'...
といったエラーが出ていることが分かりました。どうも"TRACK_NAME"というカラムが参照Tableから見つけられていないようです。Tableには確かに存在しているカラムだったので、この原因がしばらく分からなかったのですが、各DimensionsやFactsのExpression(参照Tableのカラムをどのように取り扱うか)を以下のようにダブルクオーテーションで囲むことで解消することが出来ました。
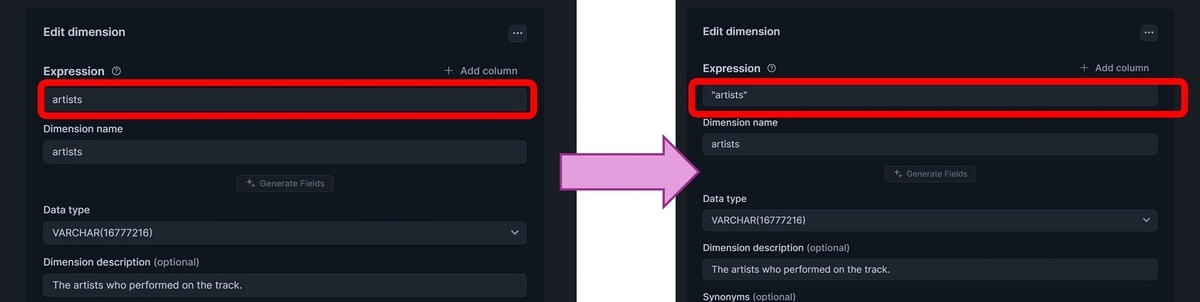
すると以下のようによい感じの結果を得ることが出来るようになりました!
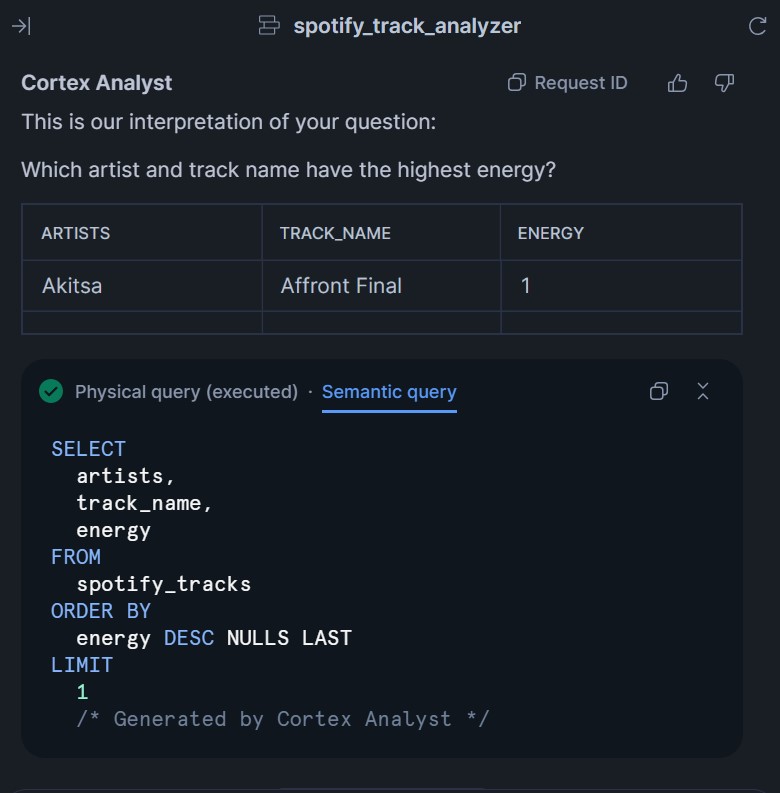
ダブルクオーテーションで囲むと上手くいった要因は、このあたりの仕様が関係しているのかな・・・と思いました。今度もう少し詳しく調べてみたいと思います。
まとめ
ということで、今回はSnowflakeのCortex Analystという機能を試してみました。Semantic ModelのYAMLの仕様を見たときは、結構敷居が高く感じたのですが、実際はUIで参照するTableやカラムを指定するだけでほぼ自動的にYAMLファイルを作ることが出来ました。おそらく色々なケースを試していくうちに制度改善要望が出てくると思いますが、その時には自分でYAMLファイルを編集して対応することが出来そうです。 また、Vector Searchを組み合わせて検索精度を改善する方法もあるようなので、こちらもこれから試してみたいと思います!