

こんにちは、CCCMKホールディングス TECH LABの三浦です。
自転車を買いました。これで遠いところまで買い物に行ったり、行きたい場所にたくさん行ける、とワクワクしています。
最近生成AIの中でもテキストを生成するAI, LLM周りにずっとかかわってきました。一方で画像生成AIはなかなか活用する機会がなく、新しいAIが登場する度に「すごいなぁ・・・」と思いながらもどんな技術なのか深堀するまでには至っていませんでした。
しかし最近はテキスト、画像、音楽、映像などを扱うことが出来る高性能なマルチモーダル生成AIも登場し始めており、テキストだけでなく画像周りの生成AIの動向や周辺技術についても把握しておきたいと感じるようになりました。
まずは最近発表された画像生成AIに関する論文の中で、自分が面白そう!と思ったものを読んでみて、最新の画像生成AIの動向について調べてみようと思いました。今回読んだ論文はEコマース用の商品紹介画像を生成する技術に関するもので、テキストと商品画像、商品を使っている人物の姿勢情報を与えることで、商品とそれを使っている自然な人物画像を生成することできる、というものです。
今回の記事の参照論文
今回の記事の作成に当たり、参照させて頂いた論文はこちらです。
Title: VirtualModel: Generating Object-ID-retentive Human-object Interaction Image by Diffusion Model for E-commerce Marketing
Authors: Binghui Chen, Chongyang Zhong, Wangmeng Xiang, Yifeng Geng, Xuansong Xie
Submitted: 16 May 2024
arXiv: https://arxiv.org/abs/2405.09985
商品を使っている自然な人物画像の生成
衣服や雑貨、家具などの商品をECサイトで見かけると、その多くが商品特徴を説明するため、実際にその商品を使用している人物の画像も掲載しています。それによってたとえば衣服であればどんなファッションを組み合わせることが出来るかイメージが付きますし、家具や雑貨だと大きさや使用方法のイメージが付くと思います。
一方でその商品を実際に使用するユーザーは年齢や性別など様々です。それらのユーザー層ごとに人物のモデルを変えて商品の画像を撮影するのはとても大変だと思います。
そこで商品の画像とそれを使っている人物の姿勢情報から、商品と様々な人物画像を生成することが出来るAIへのニーズが生まれてきます。
人物の画像を生成する技術は以前から存在しており、プロンプトと人物の姿勢情報(スケルトン画像)を与えることで意図した姿勢の人物画像を生成することが可能です。論文ではHuman Image Generation(HIG)と言及されています。一方ECサイトで使用する画像は商品とその商品を正しく使用している人物の画像が求められます。HIGでは商品の情報をモデルに伝えられませんし、その商品を自然に使っている人物の画像を生成することも難しいです。
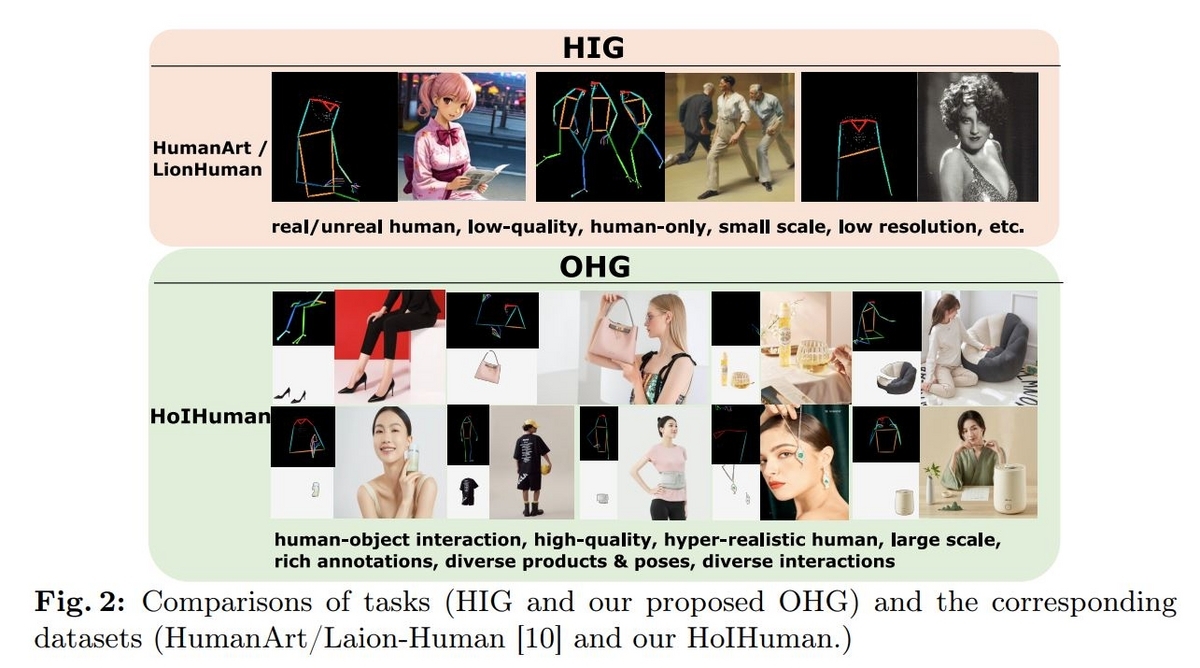
ECサイトで求められる人物画像は"とてもリアルな人物画像であること"に加え、"その商品を正しく使用していること"が求められます。論文ではこのタスクを"Object-ID-retentive Human-object Interaction Image Generation(OHG)"と呼び、それを実現するための手法としてVirtualModelというフレームワークが提案さ入れています。
制御可能な画像生成
最近の画像生成AIで使用されているDiffusion Modelは、ノイズ画像を出発点に、ノイズを除去する処理を少しずつ繰り返し行うことで自然な画像を生成することが出来る技術です。
繰り返し小さなノイズ除去処理を繰り返すことから、処理途中の間違いを補正しやすく生成画像の品質が安定している点や、処理途中で介入を行って画像生成の制御がしやすい点が特徴として挙げられます。
画像生成の制御ですぐに思い浮かぶのはDALL-E2やStable Diffusionのようなテキストによる指示でユーザーが望む画像を生成出来るモデルではないでしょうか。論文の"2 Related Works"の中では例として他にもDeepFloydやSDXLといったモデルの名前が挙げられています。モデルの構造の改良などを経て、高品質で高画質な画像が生成出来るようになってきたものの、リアルな人物画像の生成においては不自然な体のパーツを生成するような問題もまだ存在しているそうです。
リアルな人物画像生成に関する問題への対処として、姿勢の情報を入力可能なモジュールをモデルに追加する手法があります。論文ではControlNetやT2I-adapterという名前が挙げられています。これらの工夫により、リアルな人物画像は生成できるようになったものの、特定の物体と自然な接触をしている人物画像を生成することは実現出来ていないようです。
Virtual Modelのモデル構造
OHGを解くため、Virtual Modelのモデルは以下のような構造を採用しています。
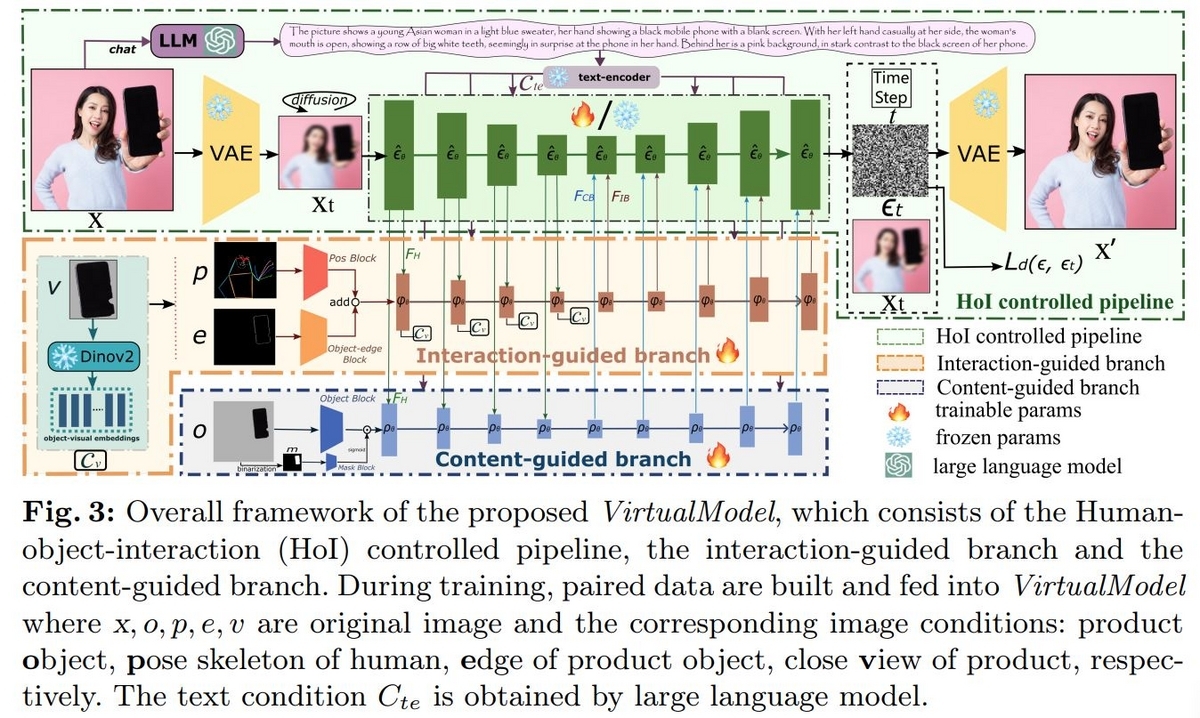
大きく3つのモジュールで構成されていて、まず画像を生成するためのHoI controlled pipelineとHoI controlled pipelineに"物体と人物の接触"の情報を与えるInteraction-guided brahch(IB)、"物体の形状"の情報を与えるContent-guided branch(CB)です。
3つのモジュールいずれもUnetというアーキテクチャが使われています。HoI controlled pipelineに比べIBとCBのUnetは小さいサイズのものが使われています。
Interaction-guided branch(IB)
IBはHoI controlled pipelineが物体と人物が自然な接触をしている画像を生成出来るように制御する役割を持っています。このモジュールは物体だけが拡大されて写った画像(v)と人物の姿勢スケルトン画像(p)、物体の輪郭画像(e)を受け取ります。画像pとeはそれぞれ複数の畳み込み層で構成されるブロックを通過して特徴量化されたのち、合算されてUnetに入力されます。一方画像vはMeta AIのDINOv2を通して特徴量化し、Unetのダウンサンプリングブロックのcross-attension層に接続されます。その他、プロンプトをCLIP(画像とテキストのマルチモーダルモデル)に通して埋め込み表現化したものもcross-attension層に接続されます。
HoI controlled pipelineのUnetとは次のように接続されます。まずダウンサンプリングブロックではHOI controlled pipelineからの出力をIBの対応するブロックに入力します。逆にアップサンプリングブロックではIBからの出力をHoI controlled pipelineの対応するブロックに入力します。
Content-guided branch(CB)
ECサイトの画像では対象の商品の画像が実物と変わってしまうと大きな問題になります。CBは商品画像の一貫性を保つ役割を持っています。CBは画像の中の物体領域だけの画像(o)を受け取ります。oをバイナリ処理し、物体領域以外をマスクした画像(m)を最初に生成します。それぞれ畳み込み処理を複数回施された後にアダマール積を計算し統合されます。あとはIBの時と同様、HoI controlled pipelineと接続されたCBのUnetで処理をされます。
Dataset(HoIHuman Dataset)
従来の人物画像データセットはECサイト用途としては解像度や品質が低かったり、人物しか映っていないなどの課題があるためVisual Modelを学習するためのデータセットを独自に収集しています。
ベースになるのはECサイトから収集された画像で、最初に物体検出モデルYOLOXでフィルタリングをかけます。具体的には人物画像の検知、最低解像度(256)を超えていること、検知された商品のカテゴリによってフィルタリングが行われます。
テキスト情報はQWenVLというVision-Language Modelを用いて抽出し、姿勢スケルトン画像はViTPoseというモデルを、商品の領域推定はGrounding-DINOとSAM(Segment Anything Model)によって抽出します。
これらのフィルタリングとアノテーション処理により3,156,125件の高品質高画質なアノテーション付きの画像が集まり、HoIHuman Datasetとしてモデル学習や検証に利用されています。また、うち5,000件がテスト用として利用されています。
推論
Visual Modelの推論時は商品領域のみの画像と人物の姿勢スケルトン画像、そして画像生成用のプロンプトを入力します。商品画像については一貫性を担保するため、生成画像に商品画像をコピー&ペーストする処理が施されます。Content Backfill(CBF)と論文では言及されています。
論文を読んでみて感じたこと
Unetについては名前は知っているものの理解が浅いので、一度PyTorchなどを使って自分で組みながら理解してみた方が良いなと感じました。特に複数のUnet同士を接続する手法は興味深くて、Unetに入力出来る形に変換出来ればテキストだけでなく音楽などのデータを使って画像生成をコントロール出来るのかもしれません。また、UnetだけでなくHoI controlled pipelineにはVAEも組み込まれており、このVAEの意味についても調べておきたいと思います。
まとめ
ということで、今回は最近の画像生成AIについての情報を掴むため、最新の画像生成AIの論文"VirtualModel: Generating Object-ID-retentive Human-object Interaction Image by Diffusion Model for E-commerce"を読んで理解したことをまとめてみました。今回特に面白いと感じたのは画像生成を制御する仕組みで、色々なことに応用できそうだと感じました。
深く理解するためには実際に手を動かしてみることが一番重要だと思うので、Diffusion Modelを自分で組んでみることにも今後チャレンジしてみたいと思いました。