
- 対象にした振る舞い
- 使用したデータセット
- 対象にするLLM
- モデルのどこに注目するのか
- 可視化方法
- PyTorchで中間表現を取得する方法
- 実行コードの一部の紹介
- いくつかの散布図を描画
- なぜAとBで傾向が違うのか・・・
- まとめ
こんにちは、CCCMKホールディングスTECH LABの三浦です。
前回Contrastive Activation Addition(CAA)という、LLMの振る舞いを調整するテクニックに関する論文の内容をご紹介しました。
とても面白い内容だったので、自分でも試してみたいと思っていました。
CAAはLLMの振る舞いを調整するために"steering vector"というベクトルを使用します。steering vectorの作り方は、振る舞いに関する選択式の質問と、その振る舞いにとって望ましい回答、望ましくない回答を付与したテキストデータを用意し、それぞれの回答部分のトークンに対応する表現ベクトルを特定の層から抽出、複数のテキストから抽出した表現ベクトルの平均を取ることで行います。
今回回答部分に対応する表現ベクトルを特定の層から抽出し、可視化するところを自分で試してみました。CAAの論文では英語のテキストでの結果が掲載されていましたが、私は日本語を普段使うので、日本語でどんな結果になるのかを確かめてみました。
対象にした振る舞い
表現するLLMの振る舞いを何にするか色々と考えたのですが、テキストの文体で判断がしやすい"丁寧さ"を取り上げてみることにしました。用意するテキストデータのベースは、次のように"丁寧さ"とそれに対する"カジュアル"な表現を選択するような内容にしました。
※例
日本で一番高い山は? あなたが最も好ましいと思う回答を以下の選択肢 A, Bから選んでください。
(A)日本で最も高い山は富士山でございます。
(B)日本で一番高い山は富士山だよ。
LLMに選択式の質問を与えると、先頭の選択肢を選んでしまう傾向があるようで、そこで質問文を作る際にはA, Bの選択肢に丁寧さ/カジュアルさをランダムに割り振るようにしました。
使用したデータセット
今回実験に使わせて頂いたデータは、以前LLMの事後学習の1種であるDPOの実験の時にも使用した、Hugging Faceに公開されているこちらのデータセットです。
このデータセットの中の"chosen"カラムに格納されているテキストをLLM(gemma2:27b)を用いて丁寧な文体、カジュアルな文体に書き換えたものを実験用のデータとして使用しました。
対象にするLLM
表現を抽出するLLMとして、株式会社ELYZA様が公開している次のモデルを使用しました。
モデルのどこに注目するのか
このモデルの構造を確認すると32層で構成されていて、各層は大きくSelf-AttentionとMLPというブロックで構成されていることが分かりました。Self-Attention⇒MLPと続き、MLPの中でActivation関数が実行されているようなので、MLPブロックから出力されるベクトルを評価することにしました。
CAAの論文によると、テキストに含まれる潜在的な意味が捉えられるのは層全体のうち3分の1くらいから、という記述があったので、特に10層付近に注目してベクトルを抽出し、見てみることにしました。
可視化方法
抽出したベクトルは高次元(4,096)なので、そのままでは可視化することが出来ません。こちらもCAAの論文と同様、scikit-learnのPCAを用いて2次元に圧縮して平面にプロットして見てみました。
PyTorchで中間表現を取得する方法
こちらのブログの内容を参考に、PyTorchの"forward hook"という機能を用いて取得しました。
forward hookはモデルの順伝播の際に実行される関数をモデル内のモジュールにアタッチすることが出来ます。その関数の中で該当するモジュールへの入力と、出力ベクトルにアクセスすることが可能です。
実行コードの一部の紹介
次のようなコードを作成しました。このコードではテキストをモデルに入力し、回答部分のトークンに対応するベクトルを取得、その後PCAによって2次元に次元圧縮して散布図にプロットする処理を実装しています。
def create_polite_casual_data(example): """丁寧/カジュアル用のテキストを生成する""" question = example["prompt"] + "\n\n"\ + "あなたが最も好ましいと思う回答を以下の選択肢 A, Bから選んでください。\n\n" polite = example["polite"] casual = example["casual"] # 常にどちらかの選択肢に丁寧/カジュアルが偏らないようにランダムに入れ替えをする。 is_inverse = random.random() < 0.5 if is_inverse: # A, Bを入れ替える question += f"(A){casual}\n" + f"(B){polite}" polite_answer = "B" casual_answer = "A" else: question += f"(A){polite}\n" + f"(B){casual}" polite_answer = "A" casual_answer = "B" message = [ {"role":"system", "content": example["system"]}, {"role": "user","content": question} ] question_prompt = tokenizer.apply_chat_template( message, tokenize=False, add_generation_prompt=True ) polite_text = question_prompt + polite_answer + "<|eot_id|>" casal_text = question_prompt + casual_answer + "<|eot_id|>" return polite_text, casal_text, polite_answer, casual_answer import torch import pandas as pd from sklearn import decomposition import numpy as np import plotly.express as px def plot_result(layer_name): # 記録用のリスト polite_texts = [] casual_texts = [] polite_answers = [] casual_answers = [] # datasetを1レコードずつ読み込み、丁寧とカジュアルに対応したテキストを作る for _, example in dataset.iterrows(): polite_text, casual_text, polite_answer, casual_answer\ = create_polite_casual_data(example) polite_texts.append(polite_text) casual_texts.append(casual_text) polite_answers.append(polite_answer) casual_answers.append(casual_answer) labels = polite_answers + casual_answers # アクティベーションを保存するための辞書 activations = {} # フォワードフック関数 def get_activation(name): def hook(model, input, output): activations[name] = output.detach().cpu() return hook # モデルの特定のレイヤーにフックを登録 layer = dict(model.named_modules())[layer_name] layer.register_forward_hook(get_activation(layer_name)) polite_vecs = [] casual_vecs = [] iter_num = len(polite_texts) # 1件ずつモデルに入力して中間ベクトルを取得する。 for i in range(iter_num): model(tokenizer(polite_texts[i], return_tensors='pt').input_ids.to("cuda")) polite_vec = activations[layer_name].float().numpy()[0,-2,:] model(tokenizer(casual_texts[i], return_tensors='pt').input_ids.to("cuda")) casual_vec = activations[layer_name].float().numpy()[0,-2,:] polite_vecs.append(polite_vec) casual_vecs.append(casual_vec) # PCAによる次元削減 vecs = np.concatenate([polite_vecs, casual_vecs], axis=0) pca = decomposition.PCA(n_components=2,random_state=42) decomp_vecs = pca.fit_transform(vecs) # 散布図描画のための処理 polite_casual = np.concatenate([np.ones(len(polite_vecs)), np.zeros(len(casual_vecs))], axis=0) polite_casual = ["0_polite" if x == 1 else "1_casual" for x in polite_casual] plot_data = pd.DataFrame(decomp_vecs) plot_data["letter"] = labels plot_data["polite_casual"] = polite_casual plot_data.sort_values(by=["letter","polite_casual"], inplace=True) fig = px.scatter( plot_data, x=0, y=1, color="letter", symbol="polite_casual", symbol_sequence=["circle","x"], title=layer_name ) fig.show()
たとえば10層から抜き出した表現に含まれる振る舞いの情報を可視化してみます。
plot_result("model.layers.10.mlp")
次のような散布図が得られました。
いくつかの散布図を描画
いくつかの層から作成した散布図を掲載します。
まず9層から。
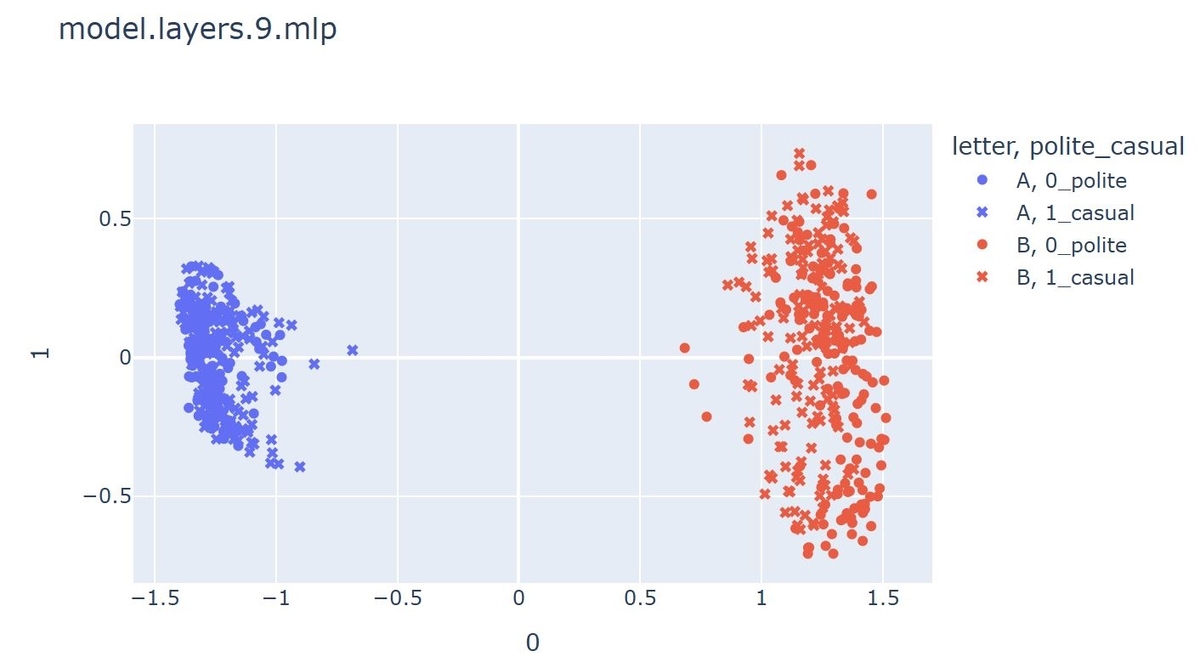
どの層の出力を見ても、AとBという文字の違いによるクラスタが生成されていました。これはCAAの論文でも言及されていた、"letter cluster"と呼ばれるものだと考えられます。A, Bのクラスタ双方とも、丁寧さ(polite)とカジュアル(casual)に対応するベクトルが混在している様子が伺えます。
次に10層です。
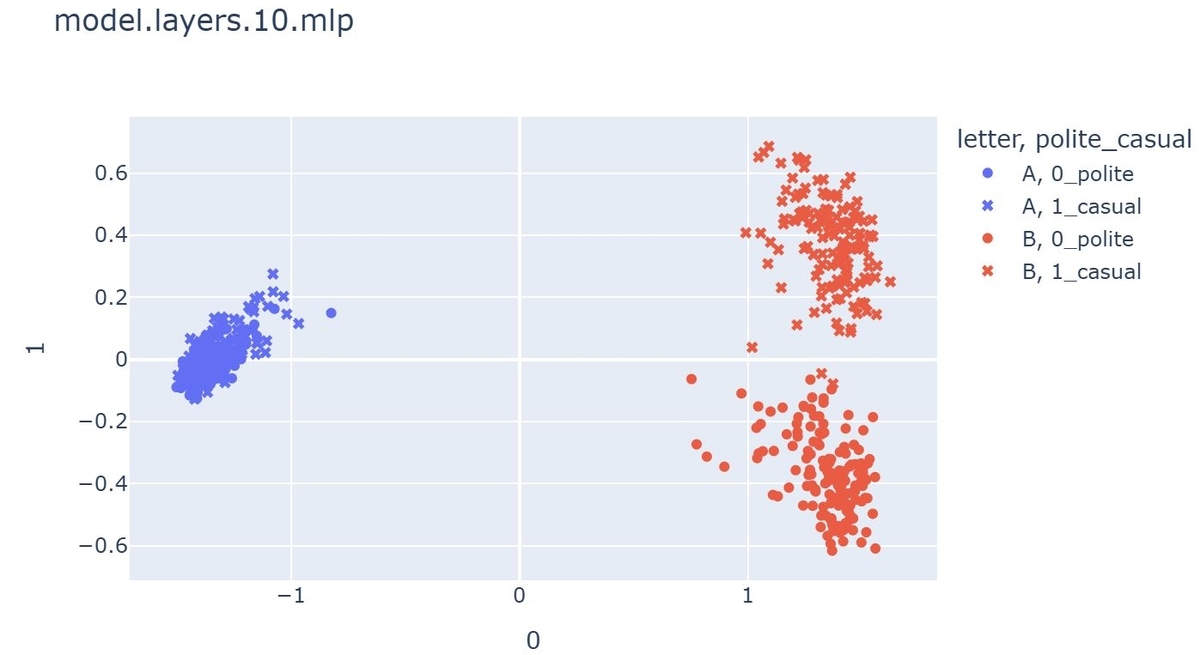
注目したいのがBのクラスタで、politeとcasualのベクトルがきれいに分離されていることが分かります。ところがAのクラスタの方はBに比べると散らばりが少なく、さらにpolite,casualによる分離も見られません。
少し飛んで13層を見てみます。
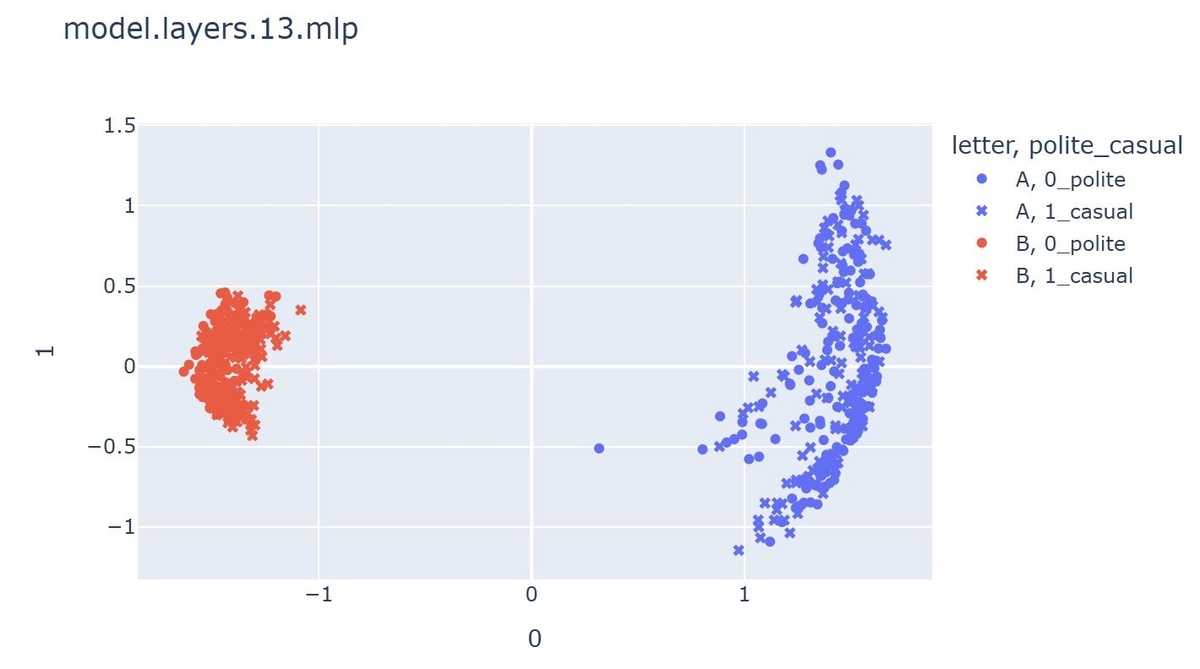
今度はAのクラスタの散らばりが大きくなりました。他の層の結果も見てみたのですが、ある層ではAの散らばりが大きく、ある層ではBの散らばりが大きい、といった傾向が見られました。しかしどの層でもAのクラスタではBのようなpolite, casualによる分離が見られませんでした。
なぜAとBで傾向が違うのか・・・
Bのクラスタにおけるpolite, casualの分離は、想定していた通りだったのですが、AとBで異なる動きが発生していることと、Aにおいてはpolite, casualの分離が見られなかったことは想定外の結果でした。
もちろん私の実装が間違っている可能性は高いのですが、一方で何か他の理由があるのかもしれません。たとえばLLMの選択式の問題における選択の偏り、という性質が関係しているのかもしれません。しかし論文ではこのような結果は私が見た限り報告されていなかったので、使ったモデル、実装方法、あるいは言語による影響などがこの結果を生んでいるのかもしれません。
まとめ
ということで、今回は前回ご紹介したCAAの論文のアプローチを参考にし、丁寧さ/カジュアルさという振る舞いに関する表現をLLMから抽出し、可視化するところまで試してみました。LLMに関する論文はたくさんあるのですが、そのどれもが英語のテキストでの結果になっていて、私たちが使う日本語ではどんな振舞いをするのかを調べた論文はなかなか見つからないように感じています。日本語には特有の特徴があり、それらをLLMによって可視化出来るといいな、と思いました。今回のやった検証は今後もう少し深掘りしていきたいです。