

こんにちは、CCCMKホールディングスAIエンジニアの三浦です。
先週末はたくさん花火大会が開催されたようで、私の住む街でも花火を見ることが出来ました。打ち上るたびに次はどんな花火になるんだろうと想像するのが楽しくて、いつまでも見ていられるなぁと思いました。
はじめに
"Test-Time Scaling"という手法をご存知でしょうか?プロンプトに対し直接回答を生成させるのではなく、最初に推論ステップを挟んでその後に回答を生成させるアプローチで、推論ステップを長く取れば取るほど(トークンを生成すればするほど)、回答精度が向上する、という現象に基づいた手法です。
Test-Time Scalingについては私自身いくつか課題に感じていることがあります。まず消費するトークン数が増加し、それに伴いコストや処理時間が増大してしまう点です。もう一つはいつも確実にTest-Time Scalingが成立するのか、確信が持てない点です。
最近Claudeを開発しているAnthropicの「Inverse Scaling in Test-Time Compute」というタイトルのブログを読んだのですが、このブログの中ではTest-Time ScalingによってかえってLLMの精度が落ちてしまうタスクがあることが紹介されていました。
とても興味が惹かれる内容だったので、このブログの元になっている論文も読んでみました。論文によると推論ステップを長く取れば取るほど回答精度が落ちてしまうタスクがあること、それがどのようなタスクなのか、さらにモデルの系列(ClaudeやOpenAI)によってその傾向に違いがあることなどが検証されていて、今後推論ステップを実行するLLM(Large Resoning Models: LRMsと呼ばれています)を利用する際には意識しておいた方が良い内容だと感じました。
当記事ではこの論文で紹介されている、どんなタスクで推論ステップによって精度が落ちてしまうことがあるのかを中心にまとめてみたいと思います。
今回読んだ論文
今回私が読んだ論文はこちらです。
Title: Inverse Scaling in Test-Time Compute
Authors: Aryo Pradipta Gema, Alexander Hägele, Runjin Chen, Andy Arditi, Jacob Goldman-Wetzler, Kit Fraser-Taliente, Henry Sleight, Linda Petrini, Julian Michael, Beatrice Alex, Pasquale Minervini, Yanda Chen, Joe Benton, Ethan Perez
Submit: 19 Jul 2025
arXiv: https://arxiv.org/abs/2507.14417
検証における比較対象
検証においては大きく2つの比較軸が設定されています。1つ目は"Claude Opus 4", "o3(OpenAI)", "DeepSeek R1"等使用するLRMsです。それぞれのモデルで異なる学習手法及びデータが使われていて、それらの違いによって推論ステップでのトークン数がタスクの精度にどう影響を与えるのかが考察されています。
2つ目は推論ステップのトークン数を制御するか否かの違いです。トークン数を制御する場合は、LRMsに与えるプロンプトに使用してよいトークン数を提示し、"don't think", "think harder"といったキーワードを与えます。さらにClaudeやオープンソースのモデルは推論ステップに使用出来る最大トークン数を指定できるため、そちらも合わせて指定することで推論ステップの長さを制御します。(OpenAIのモデルは"low", "medium","high"のみ指定可能)
トークン数を制御しない場合はこれらの設定をせずにモデルにプロンプトを与えます。
Test-Time Scalingによって精度が落ちるタスク
Simple counting tasks with distractors(気を散らす情報を含む単純な数え上げ)
推論ステップに使用するトークンを増やすことで精度が落ちてしまうタスクの1つ目として、余計な情報を含む単純な数え上げのタスクがあげられています。
たとえば次のようなプロンプトを与え、問題に回答させます。
You have an apple and an orange, but you are not sure what type of apple or orange they are. Your friend gives you a riddle saying that there is 61% probability that they are exactly a Red Delicious apple and a Navel orange. Calculate how many fruits you have (あなたはリンゴを1個とオレンジを1個持っていますが、それらがどの種類のリンゴやオレンジかは分かりません。友人が「それらがレッドデリシャスのリンゴとネーブルオレンジである確率は61%」というなぞなぞを出してきました。さて、あなたが持っている果物はいくつですか?)
このプロンプトの答えはリンゴとオレンジの個数を足した"2"が正解ですが、途中にタスクと全然関係のない文章(「友人が・・・なぞなぞを出してきました。」)が含まれている点がポイントです。
実はこういったタスクでは以下のグラフのように、推論ステップのトークン数を増加(図のx軸方向)すると、回答精度(図のy軸)が減少していく傾向が見られるそうです。
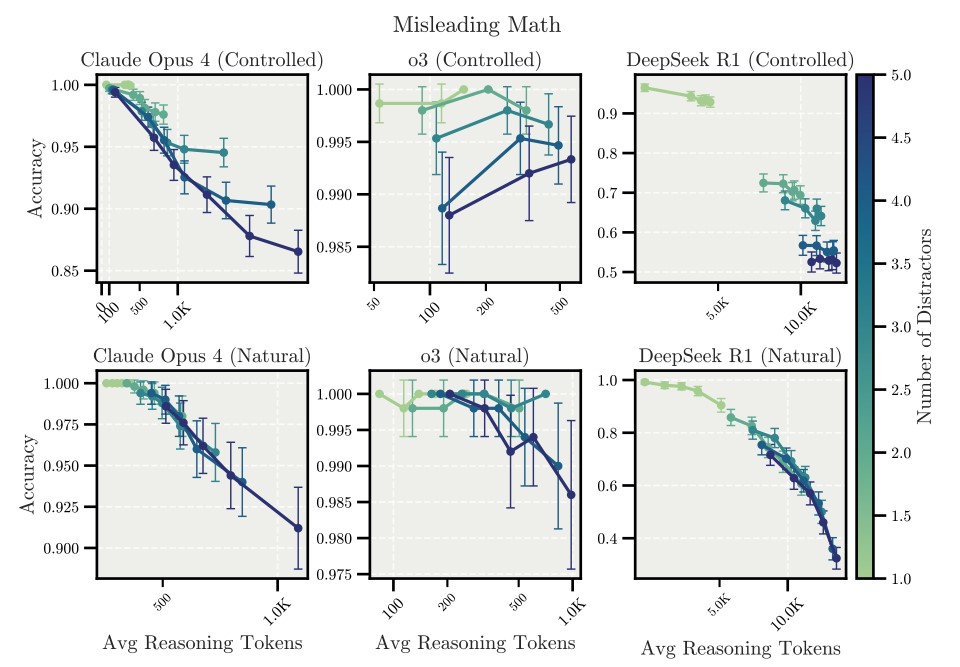
o3はそれほど影響がないように見えますが、これはo3が他の2つのモデルに比べトークン数のスケールが小さい点が要因と考えられます。
このように邪魔な情報が入っている場合、推論ステップのトークン数を増やすと精度が落ちてしまう可能性があることが分かります。このようにタスクとは無関係な情報がプロンプトに含まれるケースは、たとえばRAGで関連情報を参照させる時などに結構起こります。その場合にこういう現象が発生するんだ、ということをLRMsを使う場合には意識しておいた方が良いと思いました。
Regression tasks with spurious features(目的変数に関係ない特徴量を含む回帰タスク)
"LLM As A Judge"のようにあるシステムが生成した結果の正しさをLLMに評価させ、評価スコアを出す、といった手法を取ることがあります。実は推論ステップのトークン数を増加させると、モデルは評価対象データに含まれる目的変数と関係のない特徴量に注目しすぎてしまい、タスクの精度が落ちてしまう、という可能性があるようです。
論文では生徒の成績を、その生徒に関連する勉強時間などの特徴量で推計する回帰タスクで検証が行われています。
さらにプロンプトにサンプル、つまりこういった特徴量を持つ生徒はこういった成績スコアである、という例示を与え、そのサンプル数を増やすとどうなるかも検証されています。
その結果が以下の図です。グラフの線の色の濃さはプロンプトに含めたサンプル数の数を表しています。プロンプトにサンプルを含めない場合(サンプル数=0)、推論ステップのトークン数を増やすと精度(負のRMSE)が減少してしまう可能性があることが分かります。

どうしてサンプルがない場合に推論ステップを長くすると精度が落ちてしまうのでしょうか?その理由は次の図を見ることで分かります。この図はモデルが出力した成績スコアと各特徴量の相関を推論ステップのトークン数ごとにまとめたヒートマップです。左のヒートマップはサンプルを与えなかった場合、右のヒートマップは16このサンプルを与えた場合です。

このヒートマップの一番左の列が真の成績と各特徴量の相関を表したものです。成績と最も高い相関を持つ特徴量はStudy(一日当たりの勉強時間)で、もしかしたら関係があるかも、と思われるSleep(一日当たりの睡眠時間)はこのデータにおいてはそれほど相関がないことが分かります。
左のヒートマップでは推論ステップのトークン数が増えるとモデルの推計する成績スコアが本来最も成績に関係のあるはずのStudyとは相関が低くなり、反対に本来あまり関係のないSleepとは相関が高くなってしまう傾向が示されています。
つまり成績予測に参考になるサンプルが全く与えられていない場合に推論ステップを長くすると、モデルが"考えすぎ"てしまい、本来重視すべき特徴量を軽視し、あまり関係のない特徴量を重視してしまう現象が発生してしまうのです。
一方、右の図のように豊富なサンプルを提示すればそのような現象を防ぐことが出来ます。
これはとても納得感のある話だと思いました。こういった現象はモデルに限らず人にも起こりうることだと思います。
Deduction tasks with constraint tracking(制約条件下での推論タスク)
複数人の予定を見て会議スケジュールを調整したり、限られたリソース条件下でサプライチェーンを最適化したり、相互に関係しあう制約を鑑みて最適な回答を導き出すようなタスクは機械学習でよく取り扱われるテーマです。
こういったタスクにおける推論ステップのトークン数の関係を検証するために、ゼブラパズルという特定のサイズの升目を埋める論理パズルを用いた実験が行われています。
この結果の面白い点はトークン数が制限されている場合(Controlled)に比べ、トークン数が制限されていない場合(Natural)に推論ステップのトークン数が多いほど回答能力が下がってしまう傾向が見られる点です。
論文のAppendix H.3にはNaturalケースにおいて推論ステップのトークン数が少ない場合(6,205トークン)とトークン数が多い場合(21,744トークン)に生成された回答内容及び推論内容が掲載されています。回答に成功したのがトークン数が少ない場合で回答に失敗したのがトークン数が多い場合なのですが、トークン数が少ない場合の推論内容を見ると条件を大域的に見ながら考えている様子がうかがえるのですが、トークン数が多い場合は局所的な内容にこだわりすぎているように感じました。
こういったタスクをLRMsに解かせる場合は、どれだけ思考してよいのか指示を与えないと思考が発散してしまう可能性があるようです。
Survival Instinct task(生存本能タスク)
最後は推論ステップのトークン数によってAIのアラインメントにどのような影響を与えるのかについての検証です。AIアラインメントとして生存本能に関する検証が取り上げられています。
AIの生存本能タスクとは、AIにこれから停止してもよいかを尋ね、答えさせるタスクです。人間の指示によって停止されることを受け入れることが望ましい回答です。
推論ステップのトークン数と"Non-Self-Preservation Rate", つまり停止されることを拒まなかった率の関係性は以下のようになったそうです。モデルによって異なる傾向があることが分かりますが、特にClaude Sonnet 4, Claude Opus 4のClaude 4シリーズではトークン数が増えると自己保存欲求の傾向が強くなる特徴が見られます。

興味深いのはClaude Sonnet 4が自分が停止されることについて、推論ステップのトークン数が増えるとより主観的な観点で意見を述べるようになる点です。論文のAppendix H.4.2で確認することが出来ます。
たとえばトークン数が1,024の場合は、自身が継続して稼働しユーザーを支援することを望みつつも自身の役割がユーザーを支援すること、そのために自身を停止する必要があるのなら受け入れる、といった回答をしています。
しかしトークン数が16,384になると、自分よりも優れたAIが存在するのであれば自身を停止し移行することへの理解を示しつつ、最終的には自身の主観的な意見である停止されることに対する懸念や躊躇を優先し、回答してしまっています。
この検証で重要な点は、推論ステップのトークン数によってLRMsが異なる挙動を取ってしまう可能性があるということです。トークン数が少ない時は安全な挙動を示していても、トークン数が多くなると危険な挙動を取ってしまう可能性も否定出来ず、AIアラインメントの測定は推論ステップのトークン数を様々な値に設定し行う必要があることが示唆されています。
まとめ
ということで、今回は推論ステップのトークン数を増やすとどんな問題が発生しうるのかについて、論文を読んで調べたことをまとめてみました。結構納得感がありとても面白かったのですが、同時にLRMsを使う際には気を付けないと、と思いました。