

こんにちは、CCCMKホールディングスAIエンジニアの三浦です。
先日参加したdatabricksのDATA+AI Summitというイベントでは様々なdatabricksの新しい機能が発表されました。
その中で個人的にとても気になったのが"Agent Bricks"という機能です。
Agent BricksはプロダクトレベルのAI Agent開発をノーコードで実現することが出来るdatabricksの新しい機能です。現在一部のリージョンでbeta版で利用することが出来る状態です。私はAzure Databricksの"eastus"リージョンで試すことが出来ました。
現在Agent Bricksでは3つのタイプのAgentを作ることが出来ます。今回3つのAgentを実際に作ってみましたので、Agent Bricksでどんなことが出来るのかをまとめていきたいと思います。
Agent Bricks
PreviewsでAgent Bricksを有効にすると、左ペインに"Agents"というメニューが表示され、そこからAgent Bricksに進むことが出来るようになっています。画面は次のような感じです。
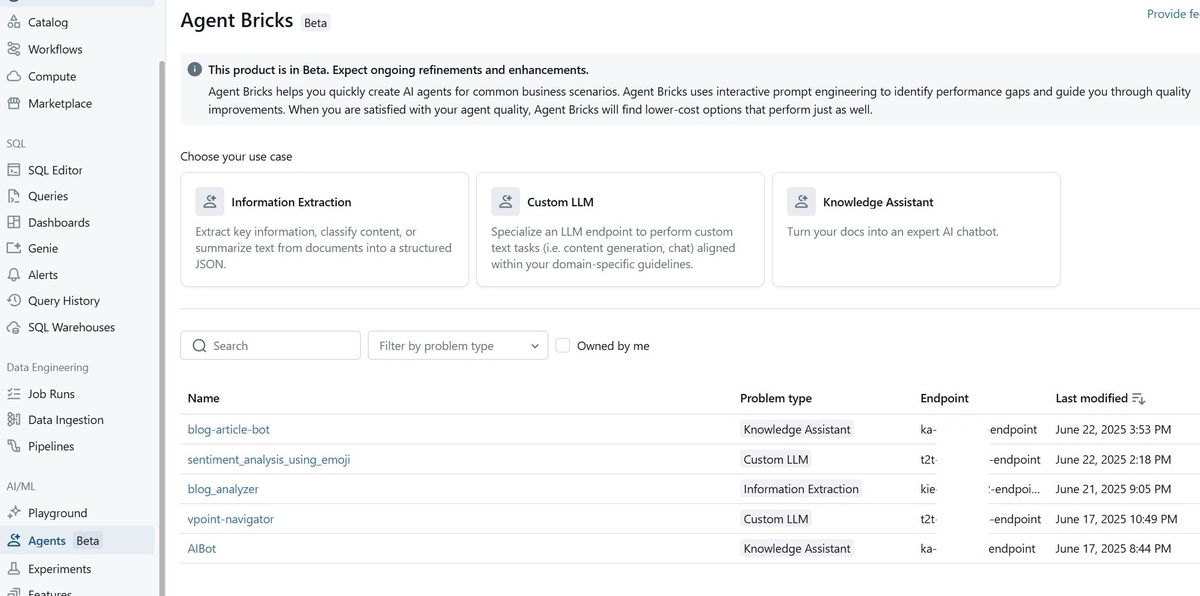
画面にあるように、現在は3つのユースケースに対応したAgentを作ることが出来ます。DATA+AI Summitで見たデモだとMulti-Agentが表示されていたと記憶しているのですが、こちらはまだ使用できないようです。今後追加されるのかな、と思っています。
現在利用できる3つのAgentは以下の通りです。
| Agent | 説明 |
|---|---|
| Information Extraction | テキストからその中に含まれる定義済みの要素をjson形式で抽出する。 |
| CustomLLM | 与えられたテキストに対し、特定のタスクを実行する。 |
| Knowledge Assistant | ユーザーの質問に対し、与えられたドキュメントを参照して回答する。 |
今回この3つのAgentを全て触ってみたのですが、なんとなくこれらはAI Agentを構成する部品で、今後追加されるであろう"Multi-Agent"を使ってこれらを組み合わせることでAI Agentが完成するのかな、という印象を受けました。
では最初にInformation Extractionから触れていきたいと思います。
Information Extraction
Information ExtractionのAgentは、テキストから事前に定められた項目をjson形式で抽出することが出来ます。たとえばソースコードファイルからその中で定義されている関数やクラス一覧を抜き出したり、議事録から参加者一覧を抜き出したり・・・といった用途で利用することが出来ます。今回、試しに私が以前書いたブログのテキストから必要な情報だけを抜き出すAgentを作ってみました。
作業の流れは次の通りです。まずサンプルになるテキストを用意してdatabricksのVolumesにディレクトリを作って格納します。次にそのディレクトリを指定し、抜き出してほしい情報のサンプルを指定します。最後にAgent Bricksから提示されるいくつかの改善アイデアを選択し、Agentを構築します。
テキストを格納したディレクトリを指定すると、次のようにAIが自動的に推計したjsonサンプルが生成されます。
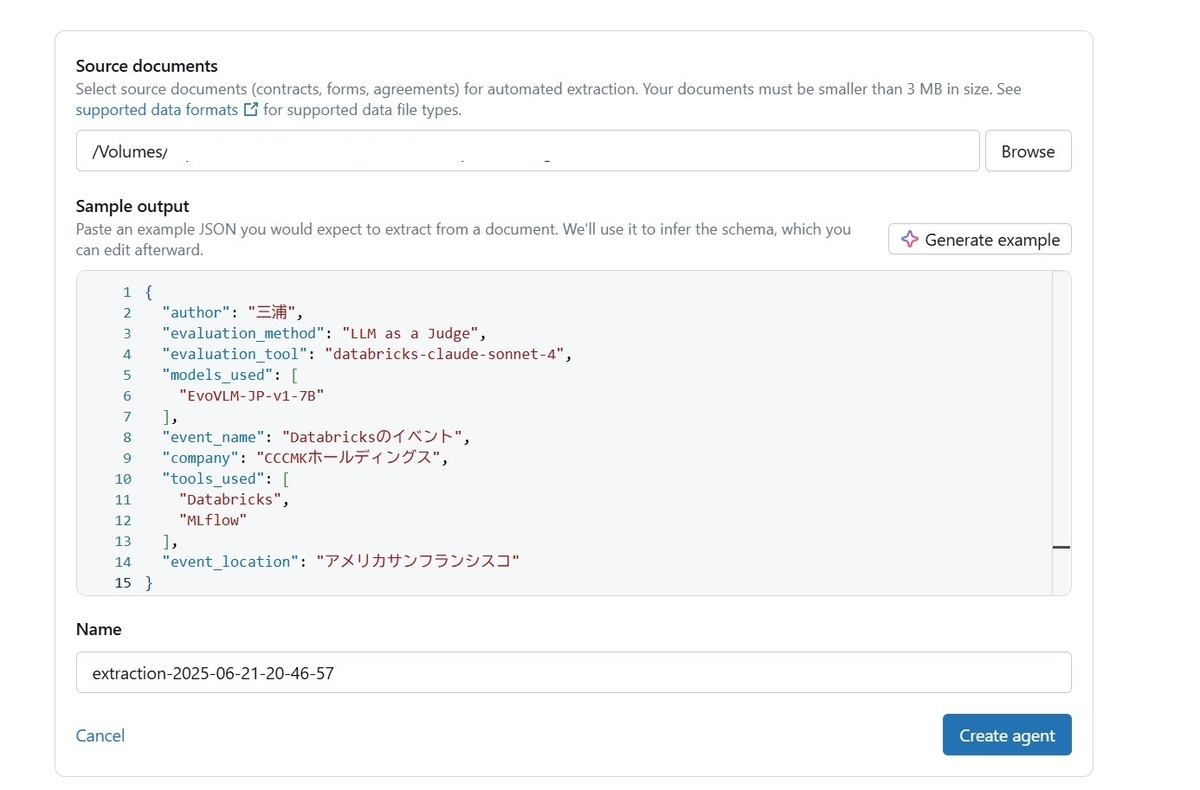
ブログのテキストから自動的に作者や所属会社、SNS用のタグやコンテンツのタイプを自動的に抽出してくれるように書き換えてみました。この状態で"Create agent"ボタンをクリックするとAgentの作成が開始されます。
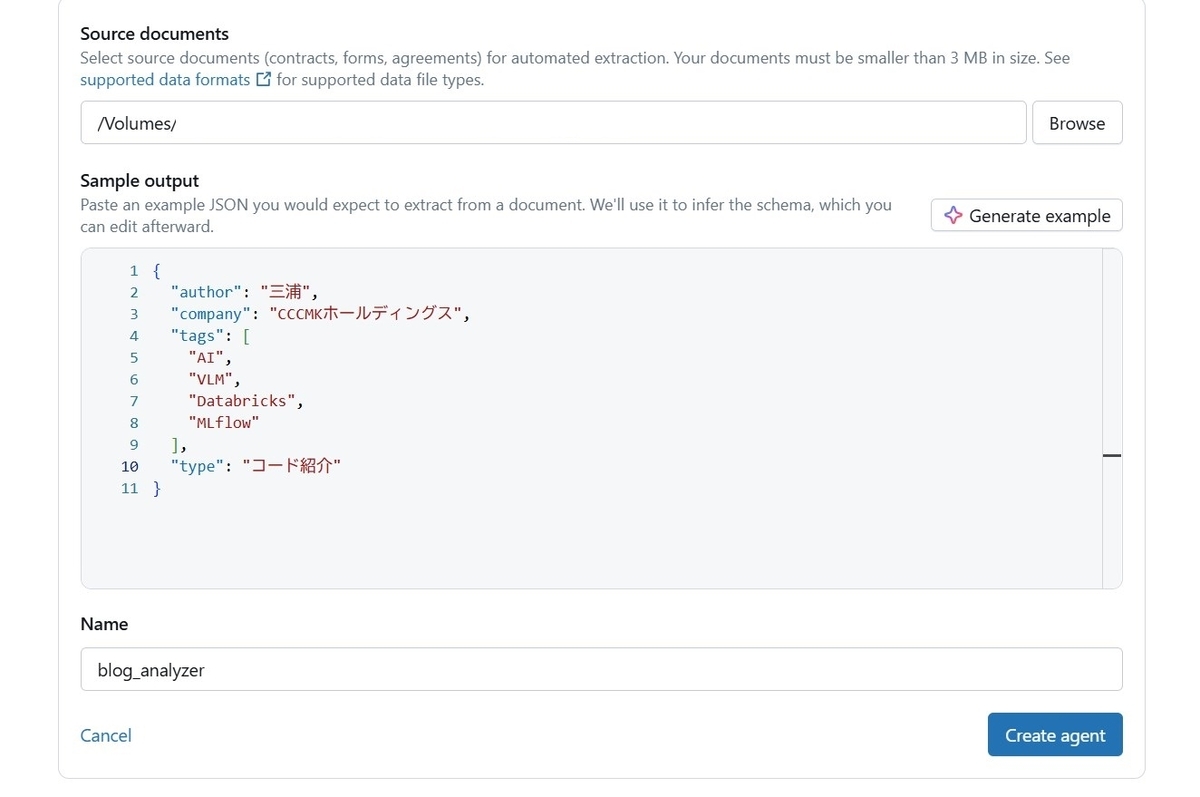
途中で"もっとこういう指示を含めたほうがいいよ"といった提示をいくつかしてくれます。例えば"author"が個人を示すのか団体を示すのかを明確にし、フォーマットも指定したほうがいい、といった提示です。
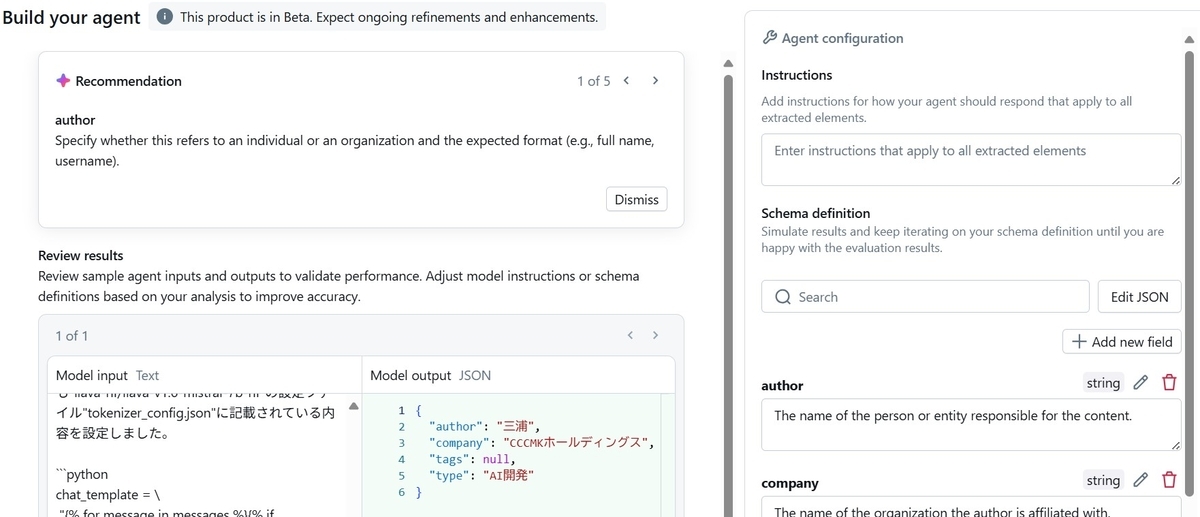
これらを受け入れることでAgentに与える指示内容をよりリッチにしていくことが出来ます。指示内容を編集し、"Update agent"をクリックすると、Agentがアップデートされ、回答結果への反映内容を確認することが出来ます。
Agentの作成が完了したら、"Use agent"をクリックし、"Extract data for all documents"に進むとテストをすることが出来ます。SQLエディタが開き、以下のようなクエリが自動的に生成されます。
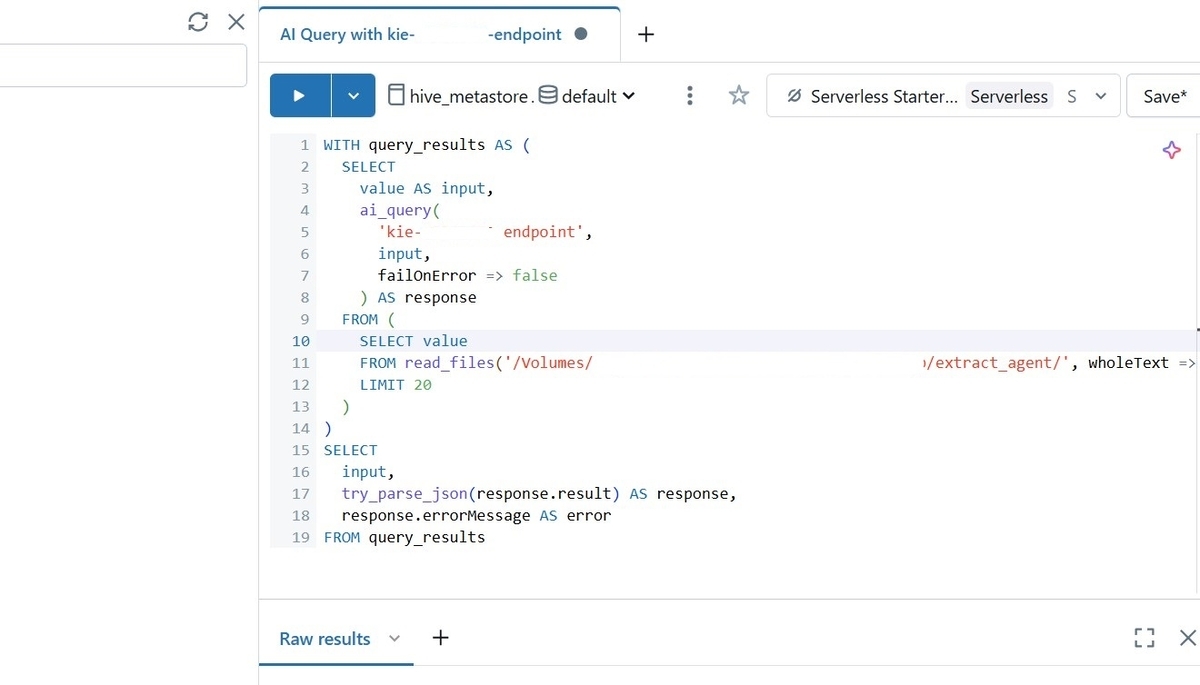
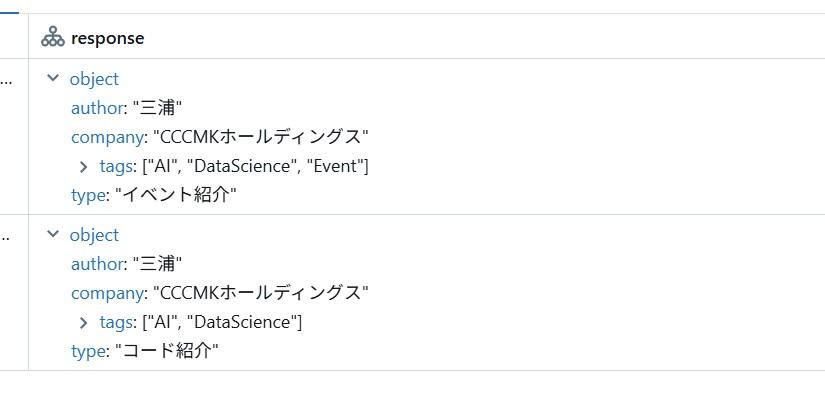
read_filesにテキストファイルが格納されたディレクトリを指定し、実行します。すると、次のような実行結果が表示され、ディレクトリに格納されたテキストファイルごとにAgentが処理した結果を確認することが出来ました。
CustomLLM
次はCustomLLMです。これは入力とそれに対して望ましい出力のペアを例示として与えると、その例示に従った内容で回答出来るLLMを作ることが出来る機能です。利用ケースとしてはテキストの分類、要約といった用途が適しています。
CustomLLMは、まず自分で入出力のサンプルを用意する必要があります。それを用意することが出来ればあとはInformation Extractionと同様の手順でAgentを作ることが出来ます。(もしかしたら内部ではLLMのファインチューニングが必要に応じて実行されているのかもしれません。)
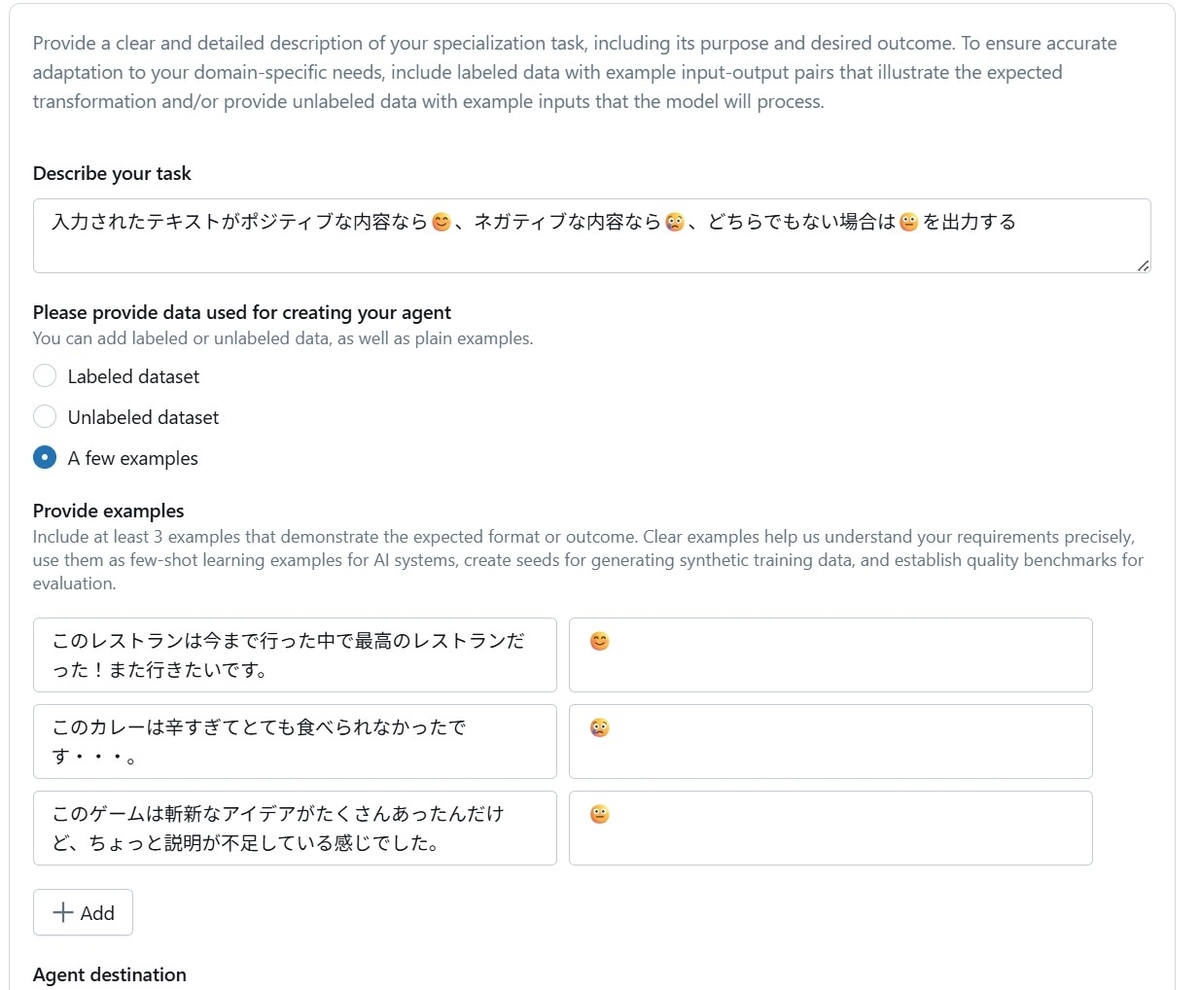
今回はテキストの感情分析をするCustomLLMを作ってみました。入力したテキストの感情によって対応する絵文字を出力させてみます。以下のように3つのサンプルを与えてみました。
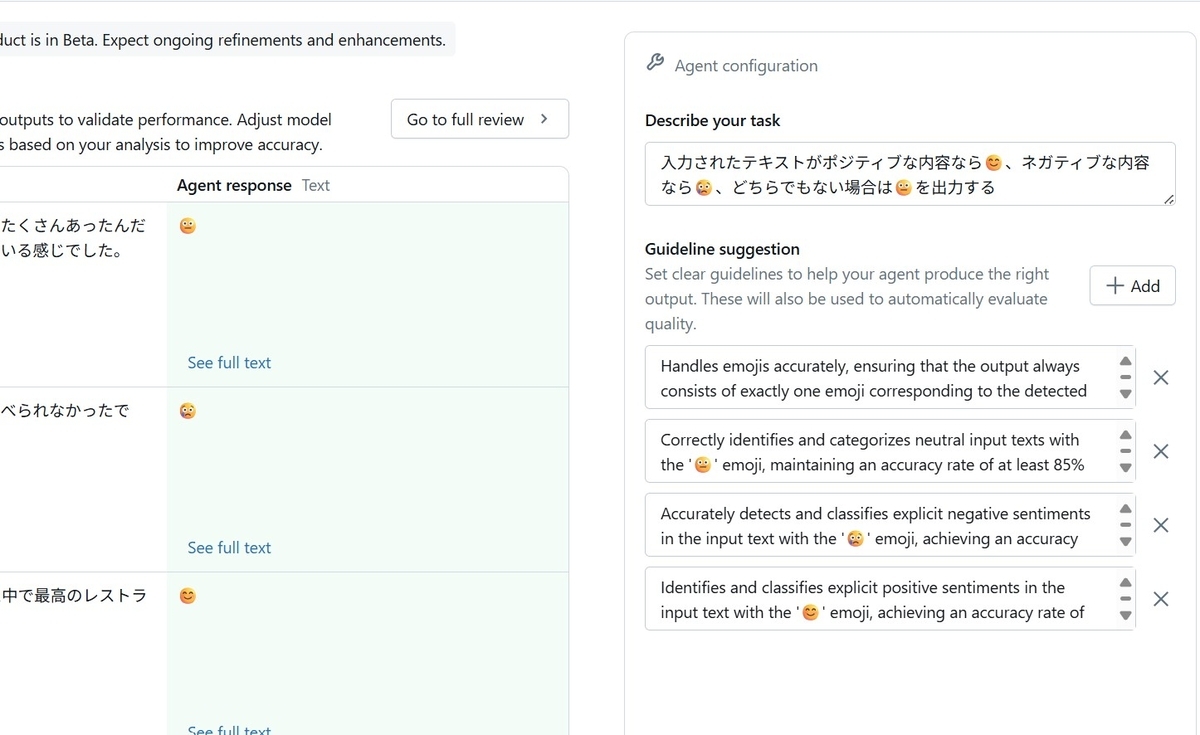
Information Extractionと同様に、Agentに与える指示の改善案が提示されます。
"Update agent"を実行し、Agentの作成が完了したらSQLエディタでテストをすることが出来ます。たとえば次のようなクエリでテストをしてみました。
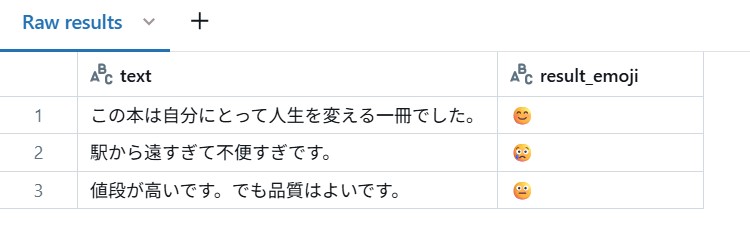
WITH comments AS ( SELECT * FROM ( VALUES ('この本は自分にとって人生を変える一冊でした。'), ('駅から遠すぎて不便すぎです。'), ('値段が高いです。でも品質はよいです。') )AS t(text) ) SELECT text, ai_query( 't2t-xxxxxx-endpoint', text ) AS result_emoji FROM comments;
結果は次のようになり、求めている結果を得ることが出来ました。
Knowledge Assistant
Knowledge Assistantは現在選べる3つのAgentの中で一番"Agent"らしいAgentだと思います。参照させるドキュメントを指定するとそこからVector Searchが生成され、RAGを使ってドキュメントを参照して回答することが出来るボットを作ることが出来ます。
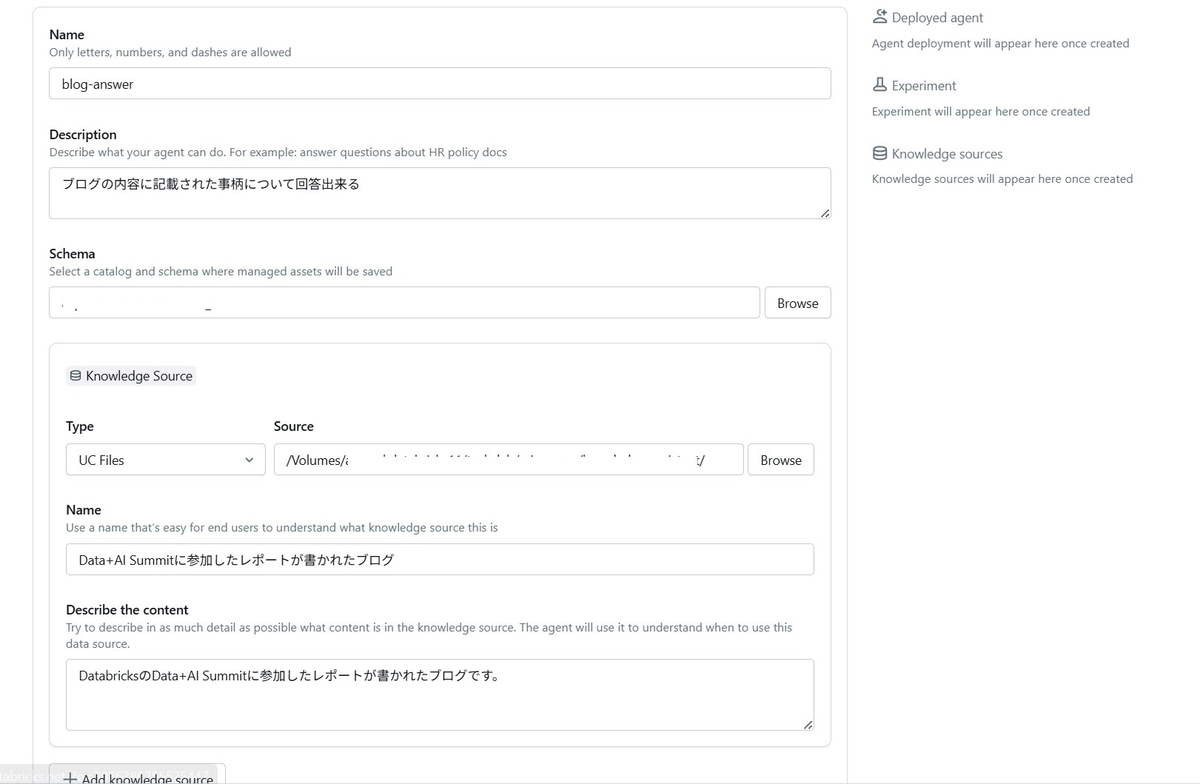
手順はとてもシンプルです。次のようにAgentの説明と、参照するドキュメントを格納したディレクトリ、Agentに必要なアセットを格納するSchemaを指定するだけでAgentの作成が完了します。(ただ、ドキュメントはPDF形式だと取り込むことが出来ませんでした。今回はマークダウン形式のテキストファイルを取り込みました。)
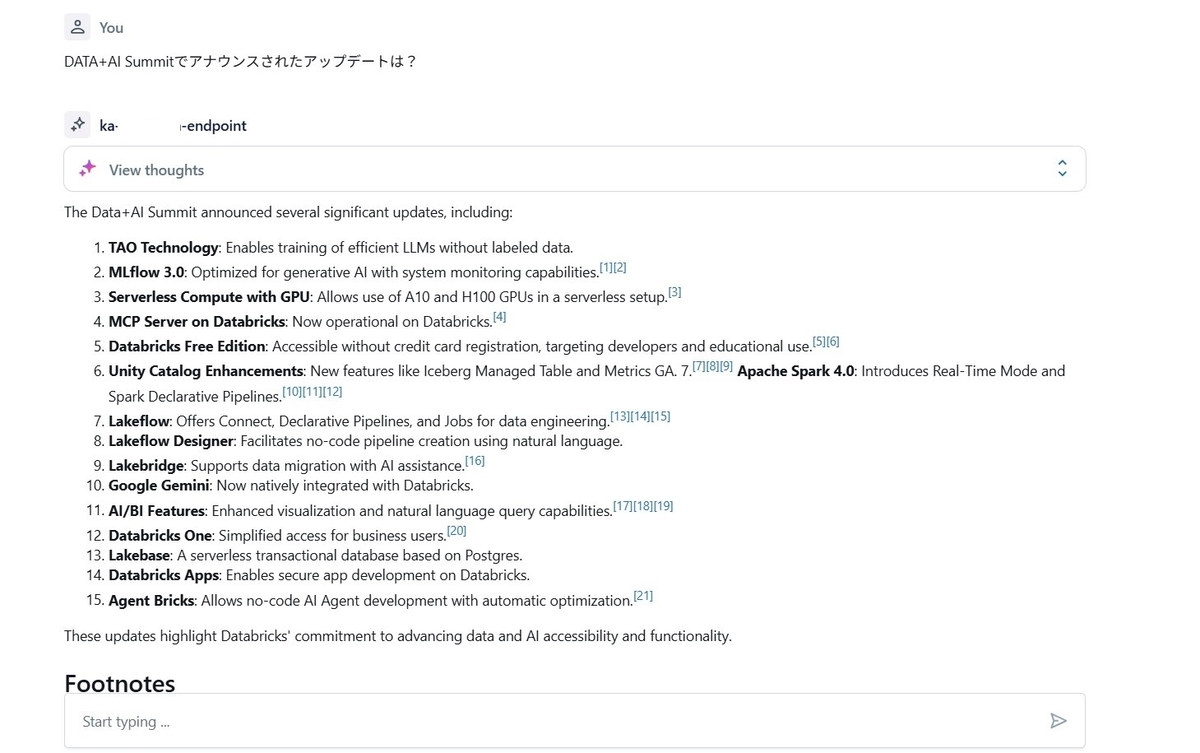
Agentの作成が完了すると、Playgroundでチャット形式でテストをすることが出来ます。
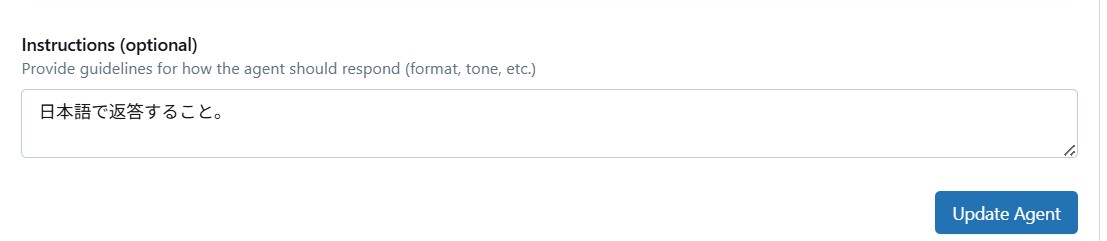
回答はあってるんですが、日本語で返してほしいです。そんな時はAgentの設定画面を開き、Instructions (optional)に"日本語で返答すること。"と指示を記載し、"Update agent"を実行することで修正をすることが出来ました。
まとめ
ということで、今回は先日のDATA+AI Summitでアナウンスされ、現在はBeta版で利用できるAgent Bricksを使ってみた話をまとめました。触ってみた感じだと、まだまだこれから機能が追加されていくんだろうな、という印象を受けました。どんな風に進化していくのか楽しみです!