

こんにちは、CCCMKホールディングスAIエンジニアの三浦です。
先日、今年6月に開催されたdatabricksのDATA+AI Summit2025を振り返るdatabricksのユーザー会に参加し、LT枠で登壇させていただきました。
大分前からLLMアプリケーション開発フレームワーク"DSPy"をテーマにしてお話したい!と考えていました。DSPyは"Programming-not prompting-LMs"というメッセージを掲げた、AIアプリケーションの構築をプロンプトエンジニアリングに頼るのではなく、Moduleの組み合わせ (プログラミング) と学習データに基づいた最適化によって実現しよう、という志向のフレームワークです。
当日の発表ではDSPyの基本的な使い方からDSPyを使った検証について発表しました。特に検証の部分は自分でも面白い結果が得られたと思っています。
今回のブログではユーザー会で発表した内容をブログ記事向けに構成しなおした内容でお届けしたいと思います。
DSPyに興味を持ったきっかけ
今年6月に開催されたDATA+AI Summitではいくつかのブレークアウトセッションに参加しました。
ブレークアウトセッションは特定のテーマに絞った各部屋で大体20分~40分くらいの長さで行われたセッションです。その中でいくつかDSPyに触れたセッションがあり、それらに参加していくうちにDSPyって面白そうだな、と感じるようになりました。
また、databricksの新しい機能紹介の中で"Agent Bricks"というAI Agentをノーコードで開発し、自動でチューニングまで実行してくれるものがあるのですが、自動チューニングの部分が"DSPyっぽい・・・"と感じたことも印象に残っていて、DSPyを自分で使ってみよう!と考えるようになりました。
DSPyで何が出来る?
LLMを利用したアプリケーション、たとえば長文を受け取ると要約を自動生成したり、商品レビューの感情分析をしたり、自動翻訳をしたりするようなものを実装する際に、LLMに与える"プロンプト"を書いたことがある経験をお持ちの方は多いと思います。
たとえば入力テキストの感情を"ポジティブ""ネガティブ""ニュートラル"のどれかを識別し、出力するような処理をLLMに指示する場合は以下のようなプロンプトになると思います。
sentiment_analyzer_prompt = \ """ あなたのタスクは与えられたテキストがポジティブ、ネガティブ、またはニュートラルであるかどうかを判断することです。 回答は必ずポジティブ、ネガティブ、またはニュートラルのいずれかである必要があります。 テキスト: {text} 回答:"""
最近のLLMだとこのプロンプトで想定通りの動作をしてくれるのですが、少し前だと"ポジティブです"のように、余計な"です"を出力したりして、その都度プロンプトの修正をした経験があります。
DSPyではこれと同じことをLLMに指示させようとすると、以下の様に実装することが出来ます。
from typing import Literal import dspy llm = dspy.LM("databricks/databricks-claude-3-7-sonnet") dspy.configure(lm=llm) class SentimentAnalyzer(dspy.Signature): """テキストの感情を分類する""" text: str = dspy.InputField() sentiment: Literal["ポジティブ", "ネガティブ", "ニュートラル"] = dspy.OutputField() sentiment_analyzer = dspy.Predict(SentimentAnalyzer)
印象的なのはLLMを使うのにコードの中にほとんど自然言語が含まれていない点です。このプログラムを実行すると、以下の様に想定通りの結果を得ることが出来ます。

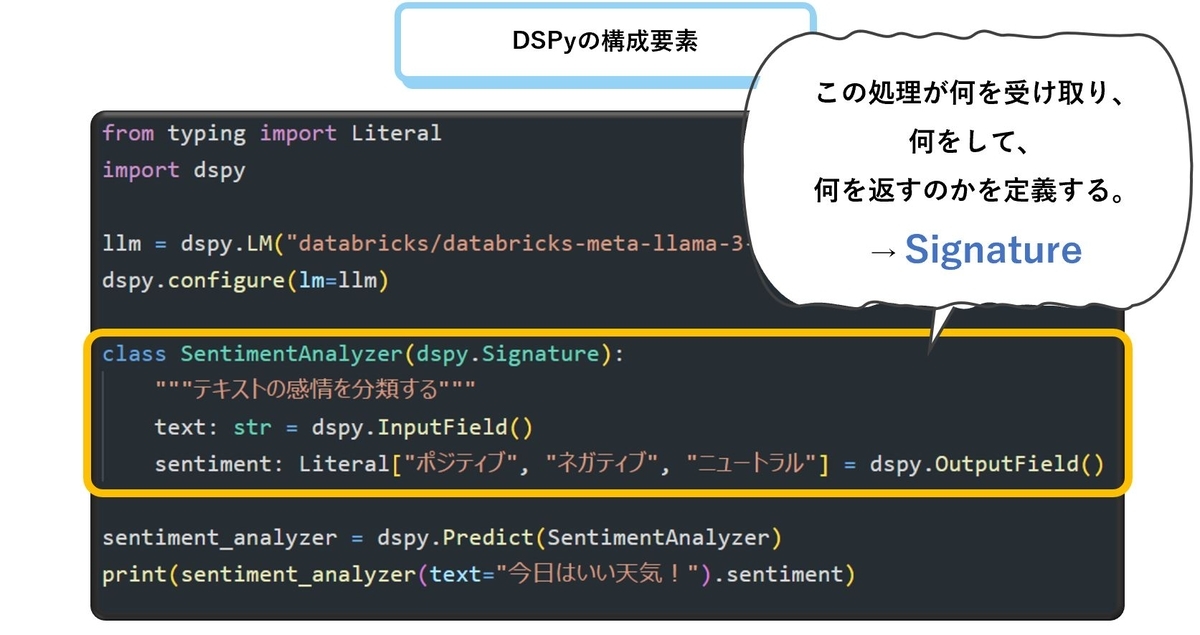
DSPyを構成する要素
DSPyではプログラムを主にSignatureとBuilt-In Moduleを組み合わせて組み立てていきます。
Signature
SignatureはLLMに"何を入力"し、"どのような処理"を実行させ、"何を出力"させるのかを指示する役割を持ちます。
Built-In Module
LLMに推論方法を指示することが出来ます。オーソドックスに推論させるものから、途中で思考プロセスを挟むChain-Of-Thoughtを実装したもの、Toolを使用させるReActを実装したものなどがあらかじめ用意されています。

Custom Moduleの開発
DSPyでは基本要素のSignatureとBuilt-In Moduleを組み合わせたより複雑なプログラムをCustom Moduleとして開発することが出来ます。
たとえば「プログラミングの歴史について調べてレポートにして」といった指示を与えると、必要な情報をWikipediaから検索し、その情報を元にレポートを書いてくれるような処理をCustom Moduleとして実装してみました。この処理の中では対象のテーマに関するレポートを書くための情報として、どういった情報が必要かを考え、それを検索するための検索クエリを生成させるステップを挟んでいます。

この処理をDSPyで実装すると、以下の様になります。
from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper def search_wikipedia_content(query: str) -> str: wiki_tool = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper(lang="ja")) return wiki_tool.run(query) class SearchPlanner(dspy.Signature): """ユーザーの要望に応えるために必要なWikipedia検索クエリを考える.""" request: str = dspy.InputField(desc="ユーザーの要望") wiki_queries: list[str] = dspy.OutputField(desc="wikipedia検索クエリ。最大3個まで") class Answer(dspy.Signature): """収集した情報を用いてユーザーの要望に回答する.""" request: str = dspy.InputField(desc="ユーザーの要望") contents: list[str] = dspy.InputField(desc="収集したWikipediaのコンテンツ") answer: str = dspy.OutputField() class MyResearchModule(dspy.Module): """ユーザーのリクエストに対し、wikipediaで多角的に情報を集めて回答するカスタムモジュール""" def __init__(self): self.search_planner = dspy.Predict(SearchPlanner) self.answer = dspy.Predict(Answer) def forward(self, request: str) -> str: wiki_queries = self.search_planner(request=request).wiki_queries if len(wiki_queries) > 3: wiki_queries = wiki_queries[:3] contents = [ search_wikipedia_content(query) for query in wiki_queries ] return self.answer(request=request, contents=contents).answer researcher = MyResearchModule()
実行結果は次のようになりました。

感情分析のLLMによる精度比較
さて、最初に触れたDSPyによるテキスト感情分析に話を戻します。DSPyではプログラムを実行する際に使用するLLMをwith句を使って切り替えることが出来ます。同じプログラムと同じ感情分析データセットを使った時、LLMの違いによってどれくらいの精度の違いが生まれるんだろう、と考えました。
そこで大きさやリリース時期が異なり、かつdatabricksのFoundation Model APIで利用可能なLLM "llama-4-maverick"と"llama-3-1-8b-instruct"でその検証を行ってみました。
検証のために書いたコードは次の通りです。
import time import dspy import mlflow def calculate_sentiment_accuracy(predict, ground_truth): """正解率を計算する""" return (predict == ground_truth).sum() / len(ground_truth) class SentimentAnalyzer(dspy.Signature): """テキストの感情を分類する""" text: str = dspy.InputField() sentiment: Literal["ポジティブ", "ネガティブ", "ニュートラル"] = dspy.OutputField() sentiment_analyzer = dspy.Predict(SentimentAnalyzer) # llama-4-maverickで実行 with mlflow.start_run(run_name="llama-4-maverick"): with dspy.context(lm=dspy.LM('databricks/databricks-llama-4-maverick')): start_time = time.time() result = test_df.apply( lambda row: sentiment_analyzer(text=row["text"]).sentiment, axis=1 ) elapsed_time = time.time() - start_time mlflow.log_metric( "accuracy", calculate_sentiment_accuracy(result,test_df["sentiment"]) ) mlflow.log_metric("elapsed_time_sec", elapsed_time) # llama3.1-8bで実行 with mlflow.start_run(run_name="llama3.1-8b"): with dspy.context(lm=dspy.LM('databricks/databricks-meta-llama-3-1-8b-instruct')): start_time = time.time() result = test_df.apply( lambda row: sentiment_analyzer(text=row["text"]).sentiment, axis=1 ) elapsed_time = time.time() - start_time mlflow.log_metric( "accuracy", calculate_sentiment_accuracy(result,test_df["sentiment"]) ) mlflow.log_metric("elapsed_time_sec", elapsed_time)
100件の検証データにおける正解率"accuracy"と推論にかかった時間"elapsed_time_sec"は次のようになりました。

"llama-4-maverick"の正解率がやはり高い結果になりましたが、処理にかかる時間もLLMのサイズが大きい分長くなる傾向があるようです。一方"llama-3-1-8b-instruct"は正解率では"llama-4-maverick"には届いていませんが、処理速度は短く抑えることが出来るようです。
もし"llama-3-1-8b-instruct"でもっと正解率を向上させることが出来れば、"llama-4-maverick"に比べより高速に感情分析を行うプログラムを得ることが出来ます。しかし、どうやってその精度を向上させることが出来るのでしょうか?従来であれば様々なプロンプトを試して精度向上を目指すと思うのですが、プロンプトの探索範囲は膨大で、また少しの表現の変化に影響を受ける不安定さもあります。
DSPyはプロンプトの最適化をOptimizerで行うことが出来ます。
DSPyのOptimizer
DSPyのOptimizerは、プログラムへの入力と求める出力で構成されるデータセット、最適化を行う際の基準になる指標、最適化手法によって主にプロンプトの指示文に当たる"Instruction"と例示にあたる"Demos"を自動的に生成し、プロンプトの最適化を行います。
最適化手法はいくつか用意されていますが、databricksのDATA+AI Summitで聞いたブレークアウトセッションで紹介されていた"MIPROv2"を使用しました。
from dspy.teleprompt import MIPROv2 train_dataset = [ dspy.Example(text=text, sentiment=sentiment).with_inputs("text") for text, sentiment in zip(train_df["text"], train_df["sentiment"]) ] # metric def validate_answer(example, pred, trace=None): return example.sentiment == pred.sentiment # Initialize optimizer teleprompter = MIPROv2( metric=validate_answer, auto="light", num_threads=24, ) # MLflowへの最適化処理の記録 mlflow.dspy.autolog(log_compiles=True, log_evals=True, log_traces_from_compile=True) with dspy.context(lm=dspy.LM('databricks/databricks-meta-llama-3-1-8b-instruct')): with mlflow.start_run(run_name="optimize_llama3.1-8b"): optimized_sentiment_analyzer = teleprompter.compile( sentiment_analyzer, trainset=train_dataset, requires_permission_to_run=False, ) with mlflow.start_run(run_name="llama3.1-8b-optimized"): start_time = time.time() result = test_df.apply( lambda row: optimized_sentiment_analyzer(text=row["text"]).sentiment, axis=1 ) elapsed_time = time.time() - start_time mlflow.log_metric("accuracy", calculate_sentiment_accuracy(result,test_df["sentiment"])) mlflow.log_metric("elapsed_time_sec", elapsed_time)
最適化後の正解率と処理速度を確認すると、"llama-3-1-8b-instruct"を使いながら正解率を"llama-4-maverick"とほぼ同じ95%まで向上させることが出来ました。

MLflowを使った最適化のロギング
DSPyのOptimizerによるプロンプトの最適化で感情分析における正解率の向上を実現することが出来ましたが、最適化中に何が行われたのかをDSPyのログだけで把握することは難しいです。
MLflowを使うとこの問題を解決することが出来ます。使い方は非常にシンプルで、mlflowをImportし、最適化処理を実行する前に次のコマンドを実行するだけでOKです。
mlflow.dspy.autolog(log_compiles=True, log_evals=True, log_traces_from_compile=True)
databricksにはMLflowが統合されており、"Experiments"に最適化中の小サンプルにおける正解率の推移や最適化によって調整されたプロンプトが自動的に記録され、確認することが出来るようになっています。

まとめ
いかがでしたでしょうか。少しでもDSPyの面白さが伝わればよいな、と思います。
私はLLMを使ったアプリケーションの開発にLangGraphを使うことが多いのですが、DSPyの方が向いているかも、と思うケースもあるように感じました。具体的には感情分析のように入力と出力、そしてLLMに何をさせたいのかが明確に決まっているケースです。一方でチャットアプリのように入出力が自由で、かつLLMに何をさせたいのかがユーザーに委ねられているようなケースはLangGraphの方が拡張しやすくて向いているように感じています。
今後はもっとDSPyを活用していきたいな、と思いました!