

こんにちは、CCCMKホールディングスTECH LAB三浦です。
「これがなかった時ってどうやって生活していたんだろう」と思うことがあります。先日初めて行った場所でスマートフォンを使って地図を見たり交通機関の時間を調べたりしていたのですが、スマートフォンがなかった時ってどうしてたんだろう、と思いました。「これがなかった時ってどうしてたんだろう」と思わせる技術が、"革新的な技術"なのかもしれません。
さて、最近読んだ論文で特に面白いなと思ったテクニックがあります。それはYoutubeやSNSなどのコンテンツ(Content)とそれを閲覧したり受け取った人たちの反応(Behavior)をLLMを通じて繋ぐテクニックで、このテクニックによって構築されたモデルをLarge Content And Behavior Models(LCBMs)と論文の中では呼んでいます。今回のこの記事では、LCBMsについて述べられている論文を読んで特に面白いなと感じた部分をまとめてみたいと思います。
参照論文
今回の記事ではLCBMsについて書かれたこちらの論文を読み、参照しています。
- Title: Large Content And Behavior Models To Understand, Simulate, And Optimize Content And Behavior
- Authors: Ashmit Khandelwal, Aditya Agrawal, Aanisha Bhattacharyya, Yaman K Singla, Somesh Singh, Uttaran Bhattacharya, Ishita Dasgupta, Stefano Petrangeli, Rajiv Ratn Shah, Changyou Chen, Balaji Krishnamurthy
- Submitted: 1 Sep 2023, last revised 16 Mar 2024
- arXivURL: https://arxiv.org/abs/2309.00359
コミュニケーションの有効性
たとえばある商品を販売している企業がその商品についての情報を動画やSNSで発信する場合を考えてみます。この場合、情報を発信する側が気にすることは、まず情報がちゃんと伝えられること、伝えたい意図が理解されること、そしてそれを受け取った人たちに発信者が望む反応を引き起こせることです。この中で特に難しくてかつ重要なのが"受信者に発信者が望む反応を引き起こせること"、つまりコミュニケーションの有効性です。
たとえば動画であればどれだけ再生されたか、リプレイされたか、高評価がされたかが受信者の反応として挙げられます。
論文では発信者が発信するコンテンツ(動画、テキストetc: Content)と受信者の反応(Behavior)をLLMを中心にしたモデルLarge Content And Behavior Models(LCBMs)で結びつけるテクニックが提案されています。LCBMsによってContentから受信者のBehaviorを予想したり、逆に受信者のBehaviorからContentの内容を推計したり、受信者のBehaviorの理由を説明するといった非常に柔軟な方法でContentとBehavior間をやり取り出来るようになります。
LCBMsで取り扱えるタスクとテキストによる表現
LCBMsではContent-Behaviorに関するタスクを"text-to-text"の形式、つまりタスクの指示文と入力データで構成されるテキストをモデルに入力し、タスクに対する回答を(数値を含む)テキストで生成させる、というアプローチを取っています。このように様々なタスクを"text-to-text"形式に置き換えて対応する、というアプローチは"T5"というモデルでも取られています。
以前T5について論文を読んでまとめた内容を記事にしていますので、よろしければご参照ください。
ではLCBMsで対応できるタスクと、それをどのように"text-to-text"形式で表現するのかについて、論文の" APPENDIX"に掲載されている内容を参照しながらまとめていきます。
behavior simulation
受信者のBehaviorを推計するタスクです。たとえばYoutubeの動画に対する各シーンのリプレイ数(Replays)というBehaviorを推計する場合は次のようなテキストをLCBMsに入力します。

この例では最初の5つのシーンのReplaysがマスクされていて、例として与えられたシーン1のReplaysに続く形でシーン2以降のReplaysを出力させるようにしています。
"Input : .. </video>"という部分には、対象の動画の埋め込み表現に対応するTokenがセットされます。また各シーンに付与されているASRはAutomatic Speech Recognitionの頭文字で自動音声認識によって抽出されたテキスト情報を表しています。
content simulation
Contentの一部を推計するタスクです。たとえば動画コンテンツの場合はASRの一部がマスクされ、そこに該当するテキストを25個のオプションから選択させる、というタスクが挙げられます。

behavior understanding
このタスクではモデルが受信者のBehaviorの理由を理解できているのかを確認します。具体的には動画コンテンツに付けられた閲覧者のコメントについて、そのコメントの感情の推計とその理由をモデルに生成させます。その結果が正しいかを検証する際には論文では6人のアノテータに0~5の得点を付けてもらうことで評価を行っていました。
content understanding
与えられたContentの内容について、モデルに説明させるタスクです。たとえばContentと合わせて"What is the color of the wall behind the man?"といった質問文を与え、"White"と回答させたり、"What does the narrator say when Emily gets into the car?"に対して"Emily was elated to see her grandma after a long time"といった回答をさせるようなタスクです。
behavior domain adaption
幅広いデータセットで事前学習されたLLMは様々なドメインのタスクに対応することが出来ます。同様に動画やSNSに対する高評価やReplayといったBehaviorで事前学習されたLCBMsもまた、事前学習に使用されたデータには含まれていないContentやBehaviorについても理解をし、対応することが可能になるそうです。たとえば広告メールに対するCTR(click-through rate)推計など、動画やSNSとは別のContentやBehaviorについても対応が可能になるそうです。
LCBMsのモデル構造
ではLCBMsのモデルはどのようになっているのかについてまとめてみます。Contentは動画や画像などの視覚的なデータとそのコンテンツが提供されるチャネルについての説明テキストに加え、ASRやOCRを利用して画像や映像から抽出されたテキストデータを含みます。LCBMsの構造は、視覚的なデータを処理する部分と、処理された視覚データとテキストデータ、Behaviorを受け取り回答を生成する部分で構成されています。論文に掲載されている図を転載します。
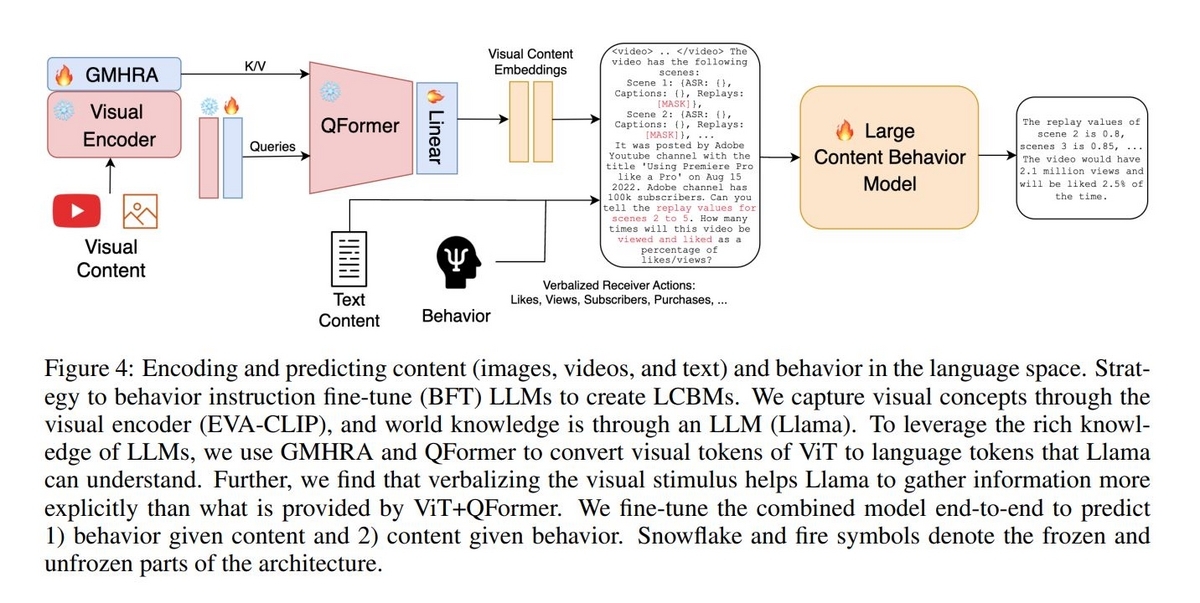
視覚データの処理部分
最初に視覚データを受け取り、ベクトル表現化する処理が行われます。この処理を担っているのがEVA-CLIPのVisual Encoderと Global Multi-Head Relation Aggregator(GMHRA)で、特にGMHRAを通すことで時系列に渡る画像特徴量を抽出することが出来るようです。
視覚データをベクトル表現にした後はテキストデータと一緒にLCBMs(LLM)に入力するため、Tokenへの変換処理が必要になります。この部分を担うのがQFormerというモジュールです。このモジュールは画像キャプショニングで使われるBLIP-2というモデルで使われていて、画像エンコーダーとLLMの橋渡しをする機能を持っています。
text-to-textの部分
Token化された視覚データとチャネル説明テキスト、ASRやOCRによるテキストデータ、Behaviorによって構成されるテキストデータを受け取り、回答をテキストで生成する部分はLlamaベースの"Vicuna-13B"というLLMが使われているそうです。
論文を読んで感じたことやまとめ
LCBMsのアプローチは様々な用途で活用できると感じました。たとえば何かをレコメンドしたい時に、この内容でこのチャネルで発信した場合、これくらいの効果が得られそう、といったシミュレーションが可能になります。またLCBMs単体で使うだけでなく、たとえば様々なツールを必要に応じて使い分けさせるAgentと組み合わせるのも面白そうだな、と感じました。
今回LCBMsの論文を読んでLLMの活用について、こういった方法もあるんだな、と新しい視点を得ることが出来たと思います。