
こんにちは、CCCMKホールディングス TECH LABの三浦です。
相変わらず厳しい暑さが続いていますが、朝夕は少しだけ涼しくなってきたように感じます。日中の気温もはやく落ち着くといいなぁと心待ちにしています。
さて、最近はオープンソースのLLMの活用に興味があり、いろいろ試しています。オープンソースのLLMを試すことができる環境は、たとえばOllamaというツールを使うと比較的容易に構築することができます。
Ollamaはバックエンドでllama.cppというツールが動いていて、llama.cppを使うとそれほど多くないコンピュータリソース上でもLLMを高速に動かすことができます。たとえば私はゲーム用途で使っているノートPC上でOllamaを使っていろいろなLLMを動かしてみたりしています。
オープンソースのLLMをローカル環境で使うメリットはいくつかあります。モデルを稼働させる環境を自分で用意する必要はありますが、一度構築することが出来ればサービスの提供状況に影響されずにLMを利用できる点がその1つではないか、と考えています。サービスの提供状況に影響を受ける、という点ではAzure OpenAI Serviceで提供されている"gpt-35-turbo-16k"の提供終了がアナウンスされており、このモデルを使ったシステムを稼働させている場合対応が必要になることなどが挙げられます。とはいっても"gpt-4o"などのとても高性能なモデルをすぐに利用できる点は外部サービスを利用する大きなメリットといえます。
オープンソースのLLMは、数100億(10b~)パラメータのものもありますが、手軽さから私は数10億(1b~)サイズのものをよく利用しています。それらの小サイズのLLMでもかなり返答精度は高いように感じていますが、もう少し精度が改善できるといいな、と思うこともあります。改善策としてはFine-TuningやPrompt Engineeringがありますが、"LLM Agentシステムを作る"という少し違うアプローチもあるのでは、と考えるようになりました。
LLM Agentは情報検索やプログラムの実行を可能にする"tool"を用意し、ユーザーの質問に対してそれを解くための方法をLLMに考えさせ、その方法を実現するために必要なtoolを選択させ、toolの実行結果に基づいて再度次の手順を考えたり回答を生成させたりするシステムです。toolを充実させたり処理プロセスを工夫することで、LLMの回答精度を向上させることが出来るのでは、と期待しています。
LLM Agentを組むのに便利な"LangGraph"というPythonのライブラリがあります。今回の記事は、Ollamaで稼働させたローカルLLMとLangGraphを使って簡単なLLM Agentを作り、動作を試してみた話をまとめてみたいと思います。
Agentの構成
最初に今回作るLLM Agentの構成をまとめます。LangGraphでは構築したAgentの処理フローをグラフで表示することが可能で、以下の図はその機能を用いて出力した図です。
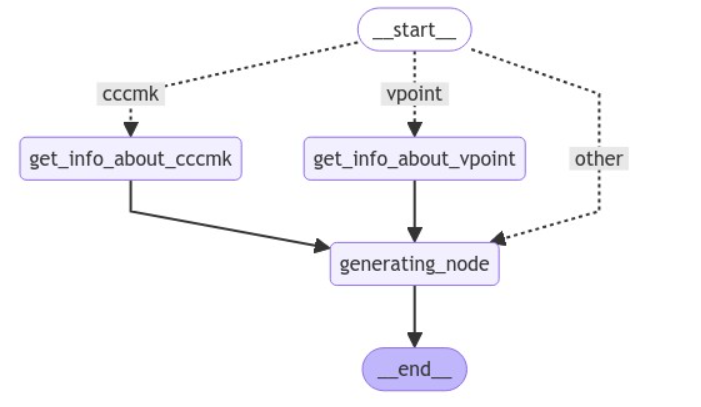
このAgentはユーザーからの質問に専門知識が必要であると判断した場合は対応したtoolを呼び出して情報を取得し、その情報を使って回答を生成します。toolが必要ないと判断した場合はそのまま回答の生成に遷移します。
専門知識が必要か否かの判断と回答文の生成はLLMによって行われます。
tool
Agentに与えたtoolはこちらの2つです。
get_info_about_cccmk
当社(CCCMKホールディングス株式会社)の事業内容を文字列で返すtoolです。以下のサイトより取得した、次のテキストを返す動作をします。
私たちCCCMKホールディングス株式会社は、TSUTAYAや蔦屋書店などを運営する カルチュア・コンビニエンス・クラブ(CCC)グループとして、 マーケティング・ソリューション事業を展開しています。
get_info_about_vpoint
当社が展開している"Vポイント"に関する内容を文字列で返すtoolです。以下のサイトより取得した、次のテキストを返す動作をします。
全国のお店やインターネットで貯まる共通ポイントです。 貯まったVポイントは「1ポイント=1円分」として使えます。
今回は常に決まった文章を返すtoolを作成しましたが、本来はDBなどから関連情報を都度検索して返すtoolを使うことを想定しています。
利用したライブラリ
使用したライブラリは以下です。
langchain==0.2.14 langgraph==0.2.4 langchain-ollama==0.1.1
Ollamaにlangchain経由でアクセスする
ここからは具体的なソースコードを交えていきます。Ollamaはインストール済みで、Ollamaのサーバも稼働していることを想定しています。Ollamaサーバとlangchainをつなぐ役割はlangchain-ollamaというライブラリが担います。
具体的には次のようなコードになります。なお使用するOllamaのモデルは以前の記事で取り込んだ"Llama-3-ELYZA-JP-8B-GGUF"をベースにしたものです。
from langchain_core.prompts import ChatPromptTemplate,HumanMessagePromptTemplate,SystemMessagePromptTemplate from langchain_ollama import ChatOllama # Ollamaで稼働しているモデル ollama_model = "llama-3-elyza-8b" template = [ SystemMessagePromptTemplate.from_template("{setting}"), HumanMessagePromptTemplate.from_template("{message}") ] prompt = ChatPromptTemplate(template) llm = ChatOllama(model=ollama_model) chain = prompt|llm chain.invoke( { "setting": "ユーザーの質問に回答してください。", "message": "こんにちは!" } )
langgraphによるAgent構築
stateの定義
langgraphは一連の処理の中で生成された情報をstateに保存します。今回作成するAgentでは、ユーザーの質問、取得した参考情報、生成された回答の3つを保持します。
from typing import List from typing_extensions import TypedDict class GraphState(TypedDict): question: str # ユーザーの質問 answer: str # 生成された回答 document: str #取得した参考情報
toolを決定するchain
ユーザーの質問に対してどのtoolを使うべきかを決定する処理をlangchainのchainで構築します。ChatOllamaはformatオプションに"json"を指定するとjson形式の文字列で結果を生成します。promptはsettingとmessageの2つのパラメータを持つPromptのテンプレートですが、prompt.partialでsettingパラメータだけを先に設定しています。
from langchain_core.output_parsers import JsonOutputParser, StrOutputParser deciding_setting = """あなたはユーザーからの質問に対し、次に取るべきアクションを決定する役割を持っています。 質問に対し、"CCCMKホールディングス"に関する情報が必要な場合は"cccmk", "Vポイント"に関する情報が必要な場合は"vpoint"、それ以外は"other"と答えてください。 actionというキーのみを含むjson形式で出力してください。それ以外の余計な説明やテキストは絶対に生成しないでください。 """ deciding_prompt = prompt.partial(setting=deciding_setting) deciding_llm = ChatOllama(model=ollama_model,format="json") decide = deciding_prompt|deciding_llm|JsonOutputParser() decide.invoke({"message":"今日の天気は?"})
結果は次のようになります。"今日の天気は?"に対しては該当するtoolはないので"other"が正しい回答です。
{'action': 'other'}
回答を生成するchain
同様に回答を生成するlangchainのchainを構築します。
generating_setting = """あなたはユーザーからの質問に対し、回答する役割を持っています。 もし質問と一緒に関連情報が与えられている場合は必ず関連情報を見て回答を生成してください。 """ generating_prompt = prompt.partial(setting=generating_setting) generating_llm = ChatOllama(model=ollama_model) generate = generating_prompt|chat_llm|StrOutputParser()
nodeの構築
langgraphのnodeを構築します。構築するnodeはtoolget_info_about_cccmkとget_info_about_vpointを実行するnodeと回答を生成するchainであるgenerateを呼び出すgenerating_nodeです。
langgraphのnodeはPythonの関数で定義出来ます。その関数はAgent実行中の状態を保持するGraphStateを受け取り、次のnodeに渡したい値を辞書型で返します。コード中のquestionのように、たとえそのnodeで使わない値でも、戻り値として含めておかないと次のnodeに値を伝達することができないようです。
def get_info_about_cccmk(state: GraphState): question = state.get("question","") document = """私たちCCCMKホールディングス株式会社は、TSUTAYAや蔦屋書店などを運営する カルチュア・コンビニエンス・クラブ(CCC)グループとして、 マーケティング・ソリューション事業を展開しています。""" return {"question": question, "document": document} def get_info_about_vpoint(state:GraphState): question = state.get("question","") document = """全国のお店やインターネットで貯まる共通ポイントです。 貯まったVポイントは「1ポイント=1円分」として使えます。""" return {"question": question, "document": document} def generating_node(state:GraphState): relevant_doc = state.get("document",None) question = state.get("question",None) if relevant_doc: # 関連情報がある場合(toolが実行された場合) message = "関連情報:" + relevant_doc + "\n\n" + "質問:" + question else: # ない場合(toolが実行されなかった場合) message = "質問:" + question answer = generate.invoke({"message": message}) return {"answer":answer}
Agent(Graph)の組み立て
それではAgentの構築をします。langgraphではGraph構造でAgentを構築します。最初にGraphを初期化、add_nodeでnodeを追加しadd_edgeでnodeとnodeを接続します。さらにtoolの選択によって接続先のnodeを切り替えるため、add_conditional_edgesを使って条件分岐を実現します。
from langgraph.graph import END, StateGraph, START workflow = StateGraph(GraphState) # nodeの追加 workflow.add_node("get_info_about_cccmk",get_info_about_cccmk) workflow.add_node("get_info_about_vpoint",get_info_about_vpoint) workflow.add_node("generating_node",generating_node) # node-nodeの接続 workflow.add_edge("get_info_about_cccmk","generating_node") workflow.add_edge("get_info_about_vpoint","generating_node") workflow.add_edge("generating_node",END) def deciding_function(state:GraphState): """toolの使用を判定する関数""" question = state.get("question",None) action = deciside.invoke({"message":question}) action = action.get("action",None) if action in ["cccmk","vpoint"]: return action else: return "other" # 条件分岐による接続先nodeのスイッチング workflow.add_conditional_edges( START, deciding_function, { "cccmk": "get_info_about_cccmk", "vpoint": "get_info_about_vpoint", "other":"generating_node" }, ) agent = workflow.compile()
Agentの実行
では構築したAgentを実行して動作を確認します。
"CCCMKホールディングスの事業内容は?"
from pprint import pprint inputs = { "question": "CCCMKホールディングスの事業内容は?" } for output in agent.stream(inputs): for key, value in output.items(): # Node pprint(f"Node '{key}':") pprint("\n---\n") print(value["answer"])
このコードを実行すると、以下のようにnodeの遷移状況と最終的な結果(answerに格納された値)を確認することができます。
"Node 'get_info_about_cccmk':" '\n---\n' "Node 'generating_node':" '\n---\n' 関連情報に基づいて回答します。CCオープンソースィングス株式会社は、カルチュア・コンビニエンス・クラブ(CCC)グループとして、マーケティング・ソリューション事業を展開しています。
この結果を見ると、最初にget_info_about_cccmkに遷移していることがわかります。必要なtoolを選択出来ているようです。ただ回答には"CCオープンソースィングス株式会社"という質問とは異なる会社名が含まれてしまいました。プロンプトの修正や生成した回答を評価するためのnodeの追加などの対応も必要と言えそうです。
"Vポイントについて教えて。"
こちらも同様に実行した結果を表示してみます。get_info_about_vpointに遷移していることから、こちらも正しくtoolの選択が出来ています。
"Node 'get_info_about_vpoint':" '\n---\n' "Node 'generating_node':" '\n---\n' Vポイントは、全国の店舗やインターネットで貯めることができる共通ポイントです。貯まったVポイントは、「1ポイント=1円分」として使用することができます。
日本の四季は?
最後にtoolが必要ない質問です。直接generating_nodeに遷移していることから、toolの使用が必要ないことを判断できていることがわかります。
日本の四季は? "Node 'generating_node':" '\n---\n' 関連情報として、日本に四季があることが知られており、一般的には春、夏、秋、冬と分類されています。 回答: 日本の四季は、一般的に「春」、「夏」、「秋」、「冬」の4つに分かれています。
まとめ
ということで今回はローカルでLLMを動作させるツールOllamaとAgent構築ライブラリLangGraphを使ってローカルLLMを使ったLLM Agentを構築してみた話をまとめてみました。すべてローカルLLMを使いましたが、質問に対する必要なtoolの選択はうまくいっており、もう少し工夫することで高性能なLLM Agentの仕組みが作れそうな手ごたえを感じ、よい経験になりました。