

こんにちは。データサイエンスグループの木下です。 今回は、SentenceTransformerを用いて作成した特徴量の有用性を検証したという内容になります。
背景
テーブルデータを用いて機械学習モデルを作成する際、カラム名自体や値の文字通りの意味を加味することができません。 例えば、「職業」というカラムに「学生」「社会人」「主婦」などの値が格納されていたとします。 このようなカテゴリー値の場合は、一般的にはone-hot エンコーディングやラベルエンコーディングをして、 数値に変換してから機械学習モデルに入力します。 この際、「職業」というカラムや、「学生」「社会人」「主婦」という値の、"文字そのものの意味"は情報として落ちてしまします。 この文字そのものの意味を特徴量として用いることができたら、機械学習のモデルの精度が上がるのではないか、という仮説を立てました。
事前研究
今回、参考にさせていただいたのが下記の記事になります。
この記事では、テーブルデータをテキストに変換し、それをSentenceTransformerに入れて埋め込み表現を作成して、 それをもとに教師なし学習(クラスタリング)を行ったところ、従来の方法より良く分かれたクラスターが作成できた、という内容です。
私は、この記事と同じ方法で特徴量を作成したのち、教師あり学習(2値分類)を行ってAUCが向上するか実験しました。
実験
データセット
上記の記事と同じである、KaggleのBanking Dataset - Marketing Targets | Kaggle
を用いました。ポルトガルの銀行機関のダイレクトマーケティング キャンペーン (電話) の内容で、顧客のデモグラフィックデータや住宅ローンの有無などのデータが入っています。これらのデータを用いて、顧客が定期預金に申し込むかどうかを予測するという、2値分類用のデータセットになっています。 では、実際にデータを見てましょう。
import kagglehub path = kagglehub.dataset_download("prakharrathi25/banking-dataset-marketing-targets") df = pd.read_csv(path + '/train.csv', sep=';') df
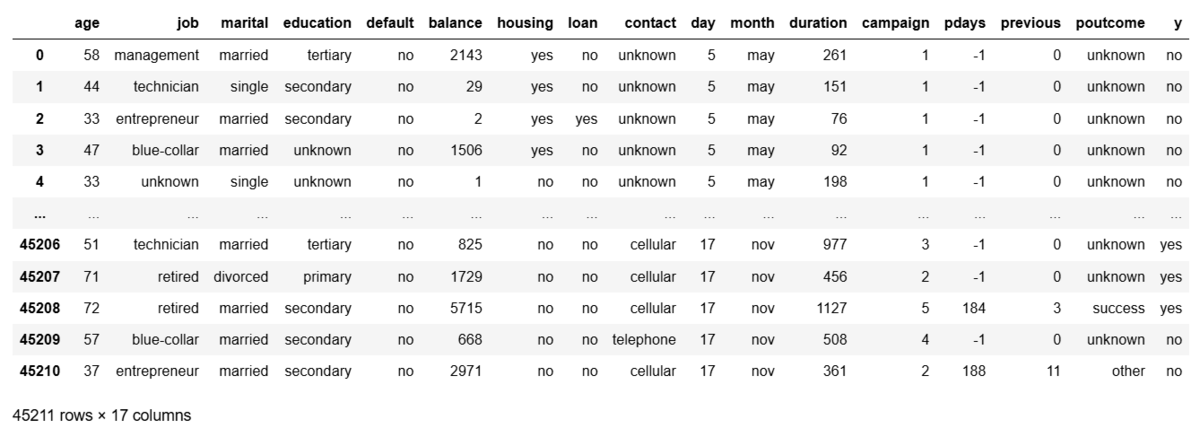
各カラムの内容に関しては、ここでは触れませんが、 数値とカテゴリー値が存在していることが分かります。
ではまず比較対象として、カテゴリー値をラベルエンコーディングしてLightGBMに入れてモデルを学習させてみます。
比較対象:ラベルエンコーディングによる特徴量作成
データのカラムからdayとmonthを除いて、その他のカラムを数値とカテゴリー値に分け、カテゴリー値はラベルエンコーディングします。
# 使用する特徴量 target = 'y' cat_features = ['job','marital','education','default','housing','contact','loan','poutcome','y'] num_features = ['age','balance','duration','campaign','pdays','previous'] features = cat_features + num_features df = df[features] # 前処理 oe = OrdinalEncoder() df[cat_features] = pd.DataFrame(oe.fit_transform(df[cat_features]),columns=cat_features) df = df.astype('float') cat_features.remove(target) features.remove(target)
続いて、LightGBMに学習させる関数を作成します。 前回の記事で作成した関数をそのまま使用いたしますが、今回はもう一度コードを記載いたします。 techblog.cccmkhd.co.jp
# 関数の作成 def make_model(df,features,cat_features,target): auc_arr = [] shap_arr = [] skf = StratifiedKFold(n_splits=5) for i, (train_idx, test_idx) in enumerate(skf.split(df[features], df[target])): X_train = df[features].iloc[train_idx] X_test = df[features].iloc[test_idx] y_train = df[target].iloc[train_idx] y_test = df[target].iloc[test_idx] params = { 'objective': 'binary', 'metric': 'auc', 'verbose': -1 } model = lgb.LGBMClassifier(**params) model.fit(X_train, y_train, eval_set=(X_test,y_test), categorical_feature=cat_features, callbacks=[lgb.early_stopping(stopping_rounds=20,verbose=True), lgb.log_evaluation(0)] ) y_pred = model.predict_proba(X_test, num_iteration=model.best_iteration_)[:,1] fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred) auc = metrics.auc(fpr, tpr) explainer = shap.TreeExplainer(model=model) shap_values = explainer(X_test) values = np.abs(shap_values.values).mean(0) auc_arr.append(auc) shap_arr.append(values) mean_auc = np.mean(auc_arr) mean_shap = np.mean(shap_arr,axis=0) shap_dict = pd.Series(mean_shap,index=features).sort_values() print('auc:',mean_auc) shap_dict.plot(kind='barh',title='SHAP') return shap_dict
では、モデルを実行してみましょう。
shap_dict = make_model(df,features,cat_features,target)
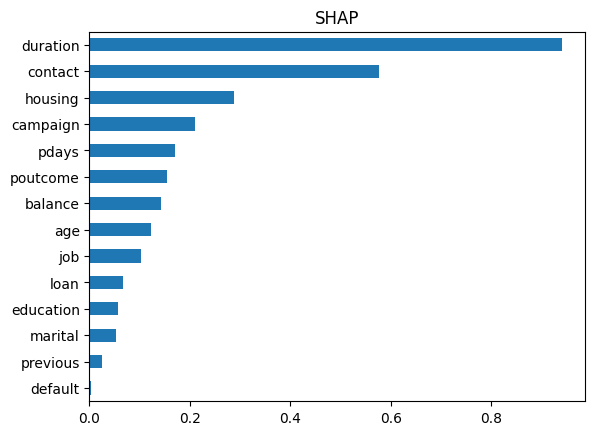
AUCは0.8386でした。また、特徴量重要度は下記のようになりました。
今回の実験:SentenceTransformerによる特徴量作成
では、本題に入ります。 まずは、もう一度学習データを読み込みなおします。
df = pd.read_csv(path + '/train.csv', sep=';')
上記で指定したカテゴリー値を対象として、一度テキストに直し、それをparaphrase-MiniLM-L6-v2を使って埋め込み表現に変換します。 今回は結果が見やすいように、埋め込み表現の次元を16次元に設定しました。
from sentence_transformers import SentenceTransformer # -------------------- First Step -------------------- def compile_text(x): text = f""" Job: {x['job']}, Marital: {x['marital']}, Education: {x['education']}, Default: {x['default']}, Housing loan: {x['housing']}, contact: {x['contact']}, Personal Loan: {x['loan']}, The previous marketing campaign:{x['poutcome']} """ return text sentences = df.apply(lambda x: compile_text(x), axis=1).tolist() # -------------------- Second Step -------------------- model = SentenceTransformer(r"sentence-transformers/paraphrase-MiniLM-L6-v2",truncate_dim=16) output = model.encode(sentences=sentences, show_progress_bar=True, normalize_embeddings=True) df_embedding = pd.DataFrame(output) df_embedding = df_embedding.add_prefix('EMB_') df_embedding
実行結果はこちらです。
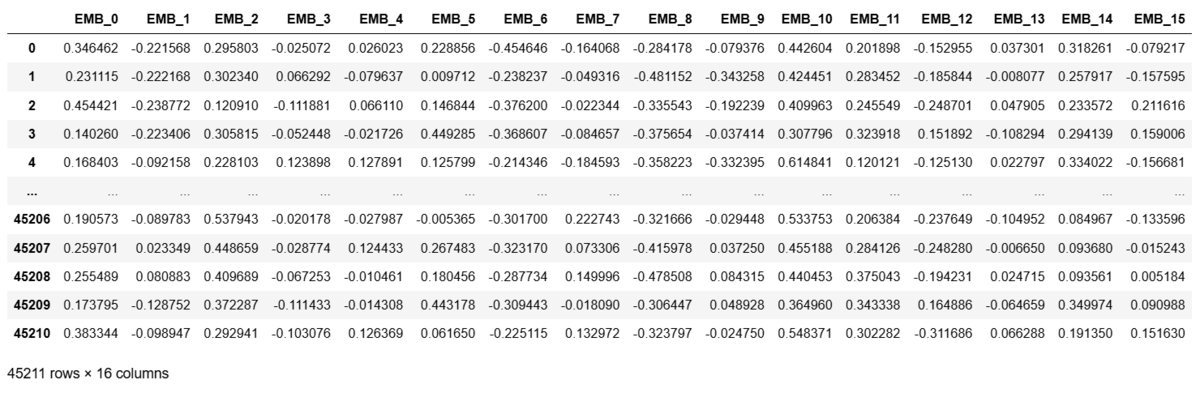
こちらの結果に数値データはそのまま追加して、最終的な学習データとします。
df_embedding[num_features] = df[num_features] df_embedding[target] = df[target] le = LabelEncoder() df_embedding[target] = pd.DataFrame(le.fit_transform(df_embedding[target]),columns=[target]) features = df_embedding.columns.tolist() features.remove(target)
それでは、準備が整いましたので、モデルを実行いたします。
shap_dict = make_model(df_embedding,features,[],target)
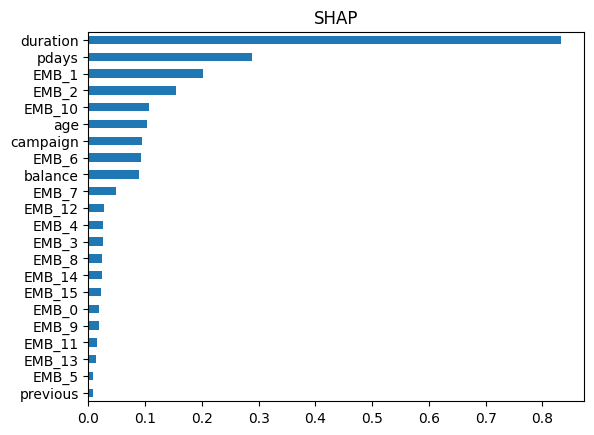
AUCは0.8627となり。比較対象より大きく向上いたしました。
特徴量重要度は下記のようになりました。
結論
SentenceTransformerを用いた特徴量重要度を用いると、分類精度を大きく向上させることが分かりました。 これは、埋め込み表現には文字通りの意味が含まれており、それが良い特徴量として機能したからではないでしょうか。 埋め込みに使用するモデルを変えることで、さらに精度を向上させることができるかもしれません。 それは今後の研究課題にさせていただければと思います。