

- Snowflake World Tour Tokyoに参加しました!
- AISQLによるドキュメントの構造化
- Streamlit in SnowflakeによるUIの実装
- とりあえず作ってみたもの
- AI_EXTRACT
- Streamlit in Snowflakeによるアプリ実装
- 課題
- まとめ
Snowflake World Tour Tokyoに参加しました!
こんにちは、CCCMKホールディングスAIエンジニアの三浦です。
9月11日~9月12日に開催されたSnowflakeの日本でのイベント"Snowflake World Tour Tokyo"に参加しました!

私も"Vポイントデータ基盤の進化と非構造化データを活用したAI-Agentによる業務改革"というセッションの中で、今取り組んでいるCortex AnalystとCortex Searchを活用したMulti-Agentの取り組みのパートで登壇させていただきました。とてもいい経験になりました。
他のセッションを聴講したり、エキスポなどで情報交換もさせていただき、すごく得るものが多いイベントでした。また来年も参加したい・・・!
AISQLによるドキュメントの構造化
さて、Snowflake World Tour Tokyoでは色々と印象に残ったことがあるのですが、特にこれはすぐに試してみたい、と思ったのがドキュメントなどの非構造化データをAISQLを利用して構造化データに加工して保存する、というアイデアです。
ビジネスで発生するデータはマニュアル・メール・提案書といったような非構造化データが大半を占めています。これらのデータにあらかじめ定義済みの属性を付与し、構造化した状態で格納しておくと人にとって検索性が向上するだけでなく、AIにとっても効率的に利用が出来る、AI-Readyな状態にすることが出来ます。
Streamlit in SnowflakeによるUIの実装
さらにドキュメントをデータベースに簡単に取り込めるようなインターフェースもあるといいな、と考えました。Snowflakeには"Streamlit in Snowflake"という機能があり、環境構築をしなくてもすぐにStreamlitのアプリをSnowflakeの中にデプロイし、公開することが出来ます。Streamlitのアプリにはテーブルなどと同様にロールによる権限を設定することが出来るため、公開範囲を設定した上でユーザーに公開できる点もメリットです。
とりあえず作ってみたもの
いきなりビジネスデータで進める前に、まず自身にとって身近なデータで何か作って検証してみようと考えました。そこで考えたのが、私たちが運営しているこのブログの記事を管理するための仕組みです。ブログの内容をPDFファイルに変換したあと、そのファイルを入力すると必要な情報が抽出され構造化データとしてテーブルに格納することが出来ます。実現したいことを図示すると以下のようになります。
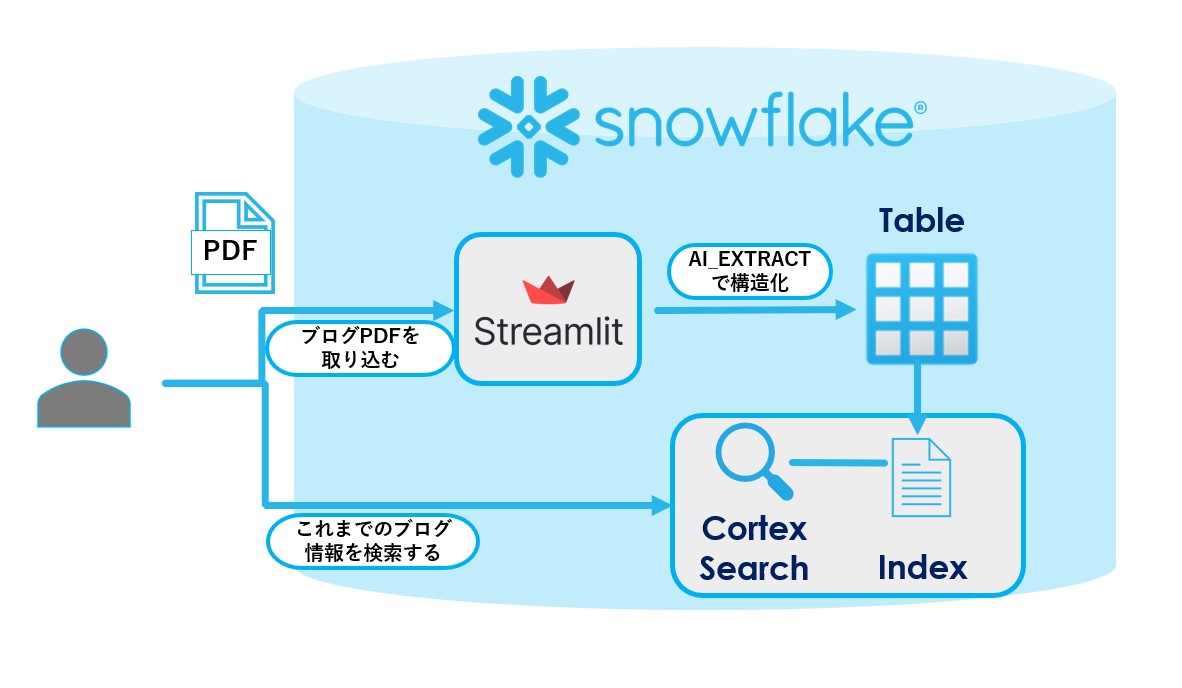
データを取り込むためのStreamlitのアプリはこのような感じです。
ブログの記事をPDFにして取り込むと、タイトル、投稿日、作者、要約がAISQL関数のAI_EXTRACTによって抽出されます。
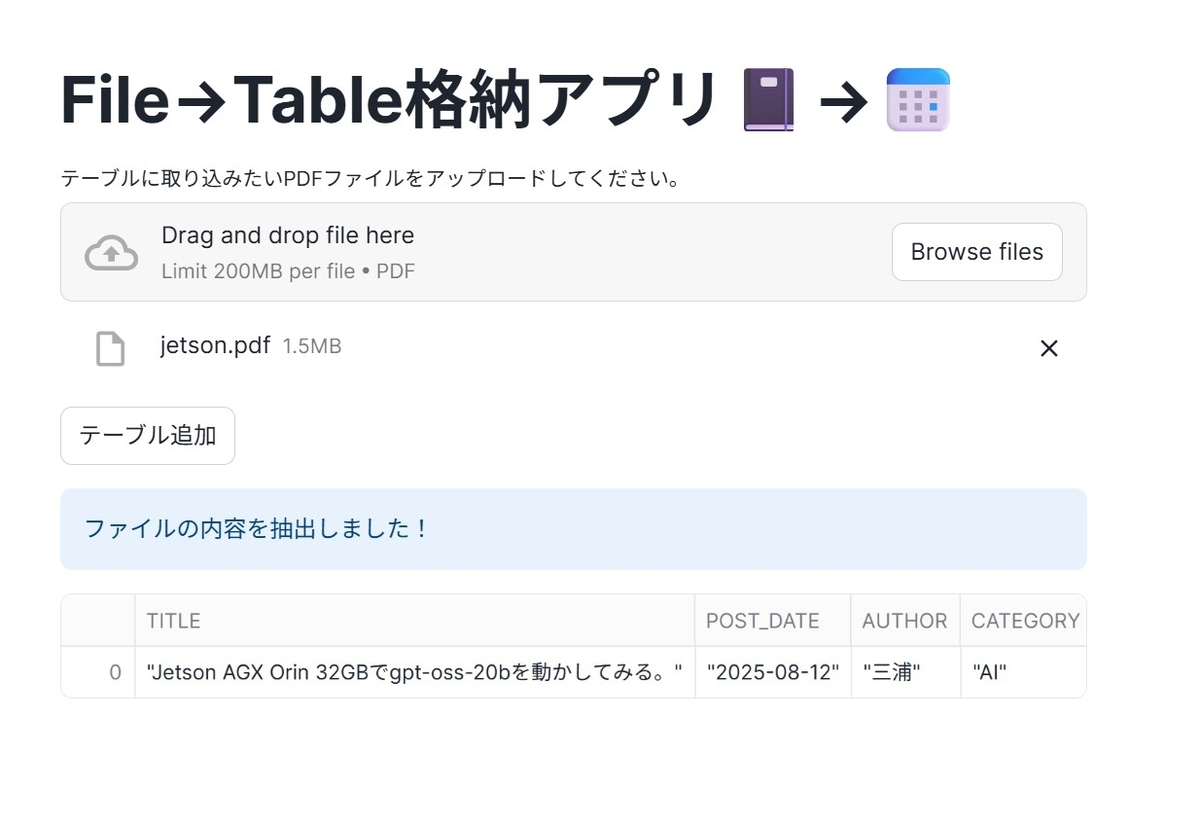
ボタンをクリックすればこの情報をテーブルに追加していくことが出来ます。
今回は進められなかったのですが、このテーブルからCortex Searchを作ることで"gpt関連の記事"のような曖昧なクエリで過去のブログを検索出来るようになると考えています。
AI_EXTRACT
今回の仕組みのキモになるのがSnowflakeのAISQLの1つであるAI_EXTRACT関数です。
AI_EXTRACTは入力されたテキストもしくはファイルから指定された情報を抽出することが出来ます。ファイルはPDFやPPTXをはじめ、様々な形式が取り込み可能で日本語にも対応しています。
一方抽出できる情報は512トークンまで、一度で抽出できる情報は100個までといった制約もあります。詳細はSnowflakeのリファレンスを参照ください。
Streamlit in Snowflakeによるアプリ実装
ここからはStreamlit in Snowflakeによるアプリの実装の詳細をご紹介します。
最初に以下のような形式でアプリで抽出したブログのデータを格納するテーブルを作りました。
CREATE OR REPLACE TABLE BLOG_LOGS ( TITLE VARCHAR, POST_DATE DATE, AUTHOR VARCHAR, CATEGORY VARCHAR, SUMMARY VARCHAR );
このテーブルと同じスキーマ内にStreamlit AppsをSnowsightのProjectsから追加します。
今回のアプリはファイルのアップロード機能が必要になるのですが、この辺りの実装はこちらのブログを参考にさせていただきました。
以下、作成したコードです。
# Import python packages from datetime import datetime import io import streamlit as st from snowflake.snowpark.context import get_active_session from snowflake.snowpark.functions import col, parse_json # 取り込んだファイルを格納するステージ STAGE_NAME = "STAGE_NAME" # ------------------------------------- # Snowflakeセッションの取得 # ------------------------------------- session = get_active_session() def get_blog_info(filename): """ブログのPDFからテーブルに書き込む情報を取得する""" df = session.sql( f""" SELECT AI_EXTRACT( file => TO_FILE('@STREAMLIT_TEMP','{filename}'), responseFormat => [ ['TITLE', 'このブログの記事のタイトルは何ですか?'], ['POST_DATE', 'このブログの記事の投稿日をYYYYMMDD形式で出して。'], ['AUTHOR', 'このブログの記事の本文に書かれているブログの作者の苗字を漢字で教えてください。'], ['CATEGORY','このブログの記事の内容はデータサイエンスにおいてどのようなカテゴリに属しますか?'], ['SUMMARY', 'このブログの記事の内容を日本語200文字程度で要約して。'] ] ):response AS contents """ ) # JSONをパース df = df.with_column("parsed", parse_json(col("contents"))) df = df.with_columns( ["TITLE", "POST_DATE", "AUTHOR", "CATEGORY", "SUMMARY"], [ col("parsed")["TITLE"], col("parsed")["POST_DATE"], col("parsed")["AUTHOR"], col("parsed")["CATEGORY"], col("parsed")["SUMMARY"] ] ) return df.select("TITLE","POST_DATE","AUTHOR","CATEGORY","SUMMARY") def main(): st.title(f"File→Table格納アプリ📓→📅") uploaded_file = st.file_uploader( "テーブルに取り込みたいPDFファイルをアップロードしてください。", type=["pdf"] ) add_btn = st.button("テーブル追加") status = st.empty() # AI_EXTRACT格納用 file_contents_df = None if uploaded_file and file_contents_df is None: now_time = datetime.now() # 日付を文字列として結合 filename = now_time.strftime("%Y%m%d%H%M%S") + ".pdf" status.info("ファイルをアップロード中・・・") file_stream = io.BytesIO(uploaded_file.getvalue()) session.file.put_stream( file_stream, f"{STAGE_NAME}/{filename}", auto_compress=False, overwrite=True ) status.info("ファイルの内容を抽出中・・・") file_contents_df = get_blog_info(filename) status.info("ファイルの内容を抽出しました!") # 一度画面に表示。 st.dataframe(file_contents_df) if add_btn: if file_contents_df is not None: status.info("テーブルに追加中・・・") file_contents_df.write.save_as_table( "BLOG_LOGS", mode="append" ) status.info("追加しました!") else: status.info("ファイルが読み込めていません。") file_contents_df = None # ------------------------------------- # アプリの起動 # ------------------------------------- if __name__ == "__main__": main()
たとえば以前書いたこちらの記事。
この記事からは以下のようなデータを抽出出来ました。いい感じに出来ていると感じました。
| カラム | 抽出した情報 |
|---|---|
| TITLE | Jetson AGX Orin 32GBでgpt-oss-20bを動かしてみる。 |
| POST_DATE | 2025/8/12 |
| AUTHOR | 三浦 |
| CATEGORY | AI |
| SUMMARY | OpenAIのオープンソース言語モデルgpt-oss-20bをエッジコンピュータのJetson AGX Orin 32GBで動かすまでの手順と実際に動かしてみたときの様子をご紹介しました。ひとまず動作出来ること、想像以上にgpt-oss-20bの回答性能が高そうであることが確認出来ました。一度モデルをダウンロードしておけばオフライン環境で動かすことが出来ますし、AGX Orinはとてもコンパクトで場所を取らないため、活用できるシーンは非常に多いと思います。 |
課題
上手くいくデータがある一方、取り込みが思ったようにいかないデータがあることも分かりました。たとえば以下の記事の作者は"高橋"が正解なのですが・・・
取り込むと当社の名前が作者として抽出されてしまっています。

AI_EXTRACTに指定する、作者(AUTHOR)を抽出するためのプロンプトは"このブログの記事の本文に書かれているブログの作者の苗字を漢字で教えてください。"のようにしているのですが、 もう少し工夫が必要なのかもしれません。
まとめ
まだ調整は必要ですが、Streamlit in SnowflakeとAI_EXTRACTを使うととても短い時間でドキュメントを構造化データとして保存することが出来る仕組みを作ることが出来ました。提案書やマニュアルといったビジネスデータに活用するとかなり便利だと思います。
AISQLは複数組み合わせることが出来て、たとえば音声をテキスト化するAI_TRANSCRIBEとAI_EXTRACTを組み合わせると音声データを構造化データとして保存できる仕組みを作ることも出来ます。
アイデア次第で色々なことが出来そうです!